
Long Presentation
Short Presentation
Descent Context
What we need and Organization
To be able to build a federation of plugs, we need several basic components:
- Reliable communications between plugs:
- publish-subscribe, multicast are basic communication primitives for programming on federated infrastructure.
- On the context of plugs, we should be able to foster and delineate small scale sub-topologies (e.g. a node and its 2-hop neighbors) and optimize communication costs.
- Federated data structures and consistency criteria to write programs
- Distributed infrastuctures have their data structures, it can be DHT for P2P network, or NoSql stores for cloud computing. Federations needs their own data structures.
- Consistency in distributed systems in rules by the CAP theorem (Consistency, Availability and Partition Tolerance). our constraints are pushing for keeping Availability and Partition Tolerance.
- If strong consistency has to be sacrificed, what kind of consistency we can reach? On which data structures?
- We need security enforcement and usage control of this social infrastructure
- Switching from centralized architecture to distributed are not solving privacy issues, it transforms them. In some way, we switch from one big brother to thousands of potential attackers. How monitoring federations and at least detect milicious?
- Basic motivations for federations is control on data usage. So we should be able to know how data on a plug is really used ?
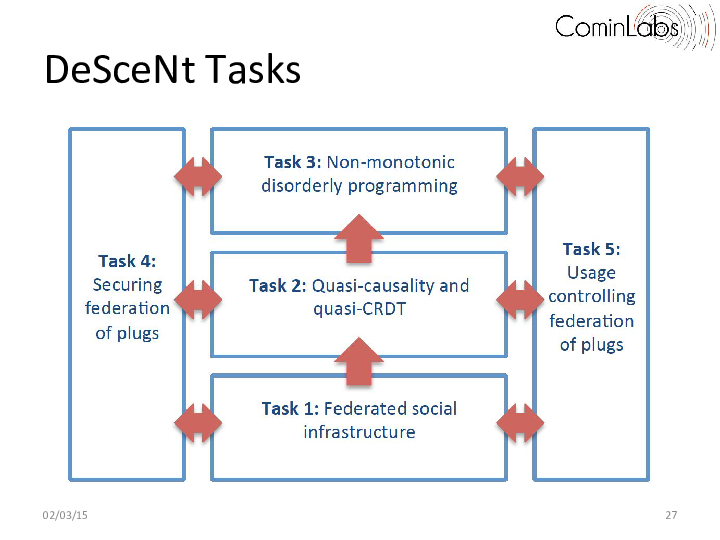
These needs motivated Descent organization the following tasks:
- Task1: Federated Social Infrastructure. We want provide to federated program developer a communication component for handling reliable communication on a federation of plugs. Such component should be able to foster and delineate small scale sub-topologies (e.g. a node and its 2-hop neighbors), that demonstrate a high level of locality, either in the data space (similar users, similar changes, similar interests), on the network plane (close to each other), or geographically (close geographically).
- Task2: Quasi-causality and quasi-CRDT. Given a federated social infrastructure produced by task 1, the objective is to provide probabilistic causal delivery and probabilistic Conflict-free Replicated Data Types (CRDT) structure such as sequences, setsand graphs.
- Task3: Non-monotonic disorderly programming. Given quasi-CRDT data structures produced by task 2, the objective is to deliver a language able to compose Quasi-CRDTand verify properties such as confluence. We aim to integrate Quasi-CRDT into dedicated languages such BloomL and go beyond monotonicity.
- Task4: Securing federation of plugs. Given a federated social infrastructure produced by task 1, the objective is to secure the federation of plugs by monitoring divergence evolution of streams on each node.
- Task5: Usage Control in federation of plugs. Given a federated social infrastructure produced by task 1, the objective is to attach usage control policies to each data retrieved from the federation and to ensure usage policies at plug level.
Task 1: Federated Social Infrastructure
“We want provide to federated program developer a communication component for handling reliable communication on a federation of plugs…”
- Build network of web browsers that adapts to number of participants : Dynamic peer sampling
- An adaptive peer-sampling protocol for building networks of browsers.Nédelec, B., Tanke, J., Frey, D., Molli, P., & Mostéfaoui, A. (2017). World Wide Web Journal, 1-33.
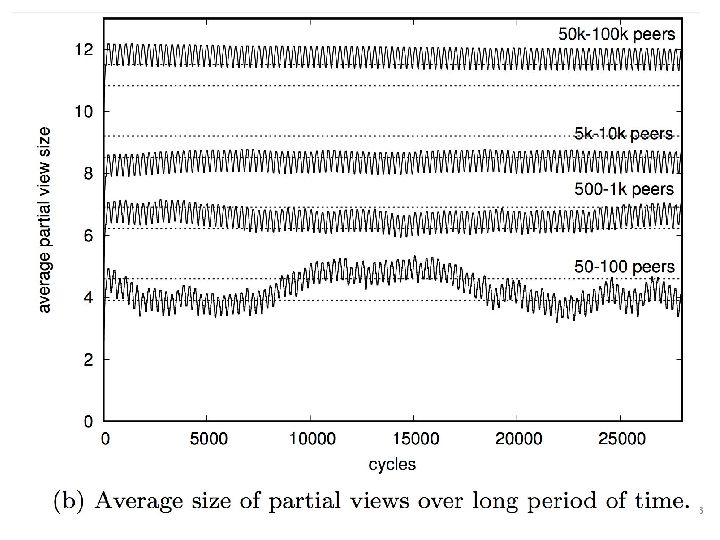 Peer-sampling protocols constitute a fundamental mechanism for a number of large-scale distributed applications. The recent introduction of WebRTC facilitated the deployment of decentralized applications over a network of browsers. However, deploying existing peer-sampling protocols on top of WebRTC raises issues about their lack of adaptiveness to sudden bursts of popularity over a network that does not manage addressing or routing. Spray is a novel random peer-sampling protocol that dynamically, quickly, and efficiently self-adapts to the network size. Our experiments show the flexibility of Spray and highlight its efficiency improvements at the cost of small overhead. We embedded Spray in a real-time decentralized editor running in browsers and ran experiments involving up to 600 communicating web browsers. The results demonstrate that Spray significantly reduces the network traffic according to the number of participants and saves bandwidth.
Peer-sampling protocols constitute a fundamental mechanism for a number of large-scale distributed applications. The recent introduction of WebRTC facilitated the deployment of decentralized applications over a network of browsers. However, deploying existing peer-sampling protocols on top of WebRTC raises issues about their lack of adaptiveness to sudden bursts of popularity over a network that does not manage addressing or routing. Spray is a novel random peer-sampling protocol that dynamically, quickly, and efficiently self-adapts to the network size. Our experiments show the flexibility of Spray and highlight its efficiency improvements at the cost of small overhead. We embedded Spray in a real-time decentralized editor running in browsers and ran experiments involving up to 600 communicating web browsers. The results demonstrate that Spray significantly reduces the network traffic according to the number of participants and saves bandwidth.
- Polystyrene: The Decentralized Data Shape that Never Dies
- Simon Bouget, Hoel Kervadec, Anne-Marie Kermarrec, François Taiani, Proceedings of the 2014 IEEE 34th International Conference on Distributed Computing Systems (ICDCS 2014), 30 June – 3 July 2014, Madrid, Spain, pp. 288-297 (10p), abstract, complete document, talk, doi: http://dx.doi.org/10.1109/ICDCS.2014.37.
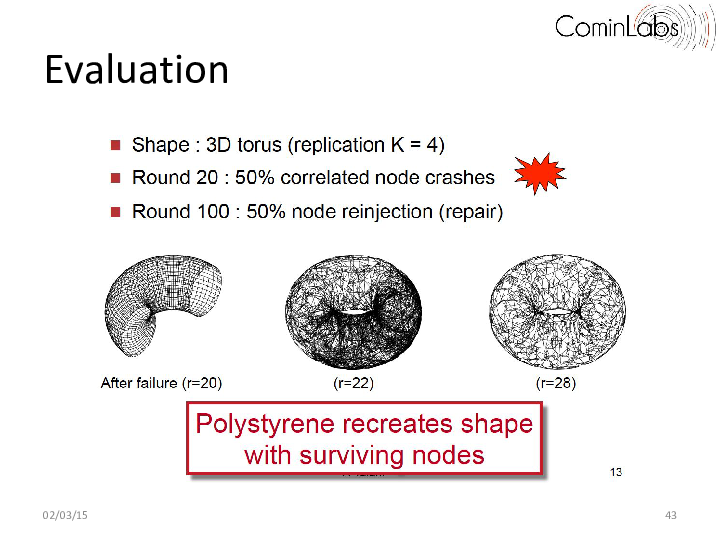
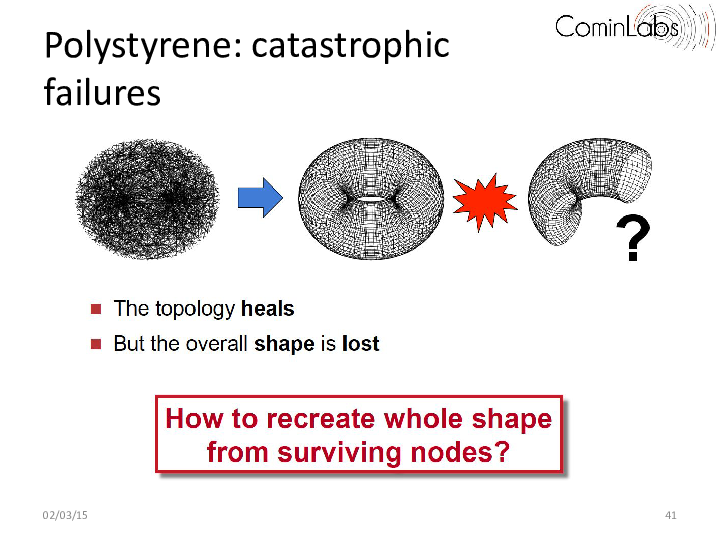
One key building block is the construction of emerging topologies created using decentralized topology construction protocols. Such decentralized topology construction protocols organize nodes along a predefined topology (e.g. a torus, ring, or hypercube) and can in many contexts ranging from routing and storage systems, to publish-subscribe and event dissemination. These protocols however typically assume no correlation between the physical location of nodes and their positions in the topology, and, as a result, do not handle catastrophic failures well, in which a whole region of the topology disappears. When this occurs, the overall shape of the system typically gets lost. This is highly problematic in applications such as the ones considered in the Descent project, in which overlay nodes are used to map a virtual data space, be it for routing, indexing or storage. In this work, we proposed a novel decentralized approach that can recover from catastrophic correlated failures and reform the system’s original topology when this happens even if a large (consecutive) portion of the topology fails. Our approach relies on the dynamic decoupling between physical nodes and virtual ones enabling a fast reshaping. Our results show that a 51,200-node torus converges back to a full torus in only 10 rounds after 50% of the nodes have crashed. Our protocol is both simple and flexible and provides a novel form of collective survivability that goes beyond the current state of the art.
More precisely, the shape-preserving decentralized protocol we propose (called Polystyrene), comes in the form of an add-on layer that can be plugged into any decentralized topology construction algorithm. The simple intuition behind our work consists in decoupling the positions of the nodes in the topology from the nodes themselves. As in existing epidemic topology construction protocols (e.g. T-Man, Vicinity), each Polystyrene node starts with one position. However, contrary to traditional topology construction systems, we allow Polystyrene nodes to change their positions (i.e. migrate) when nodes fail, and to redistribute themselves around the target shape. As a result, the original shape is maintained, albeit at a lower sampling density, resulting from the lower number of surviving nodes.
We enable this migratory behavior by storing two sets of data points per node: a first set of guest data points hold the points the node is in charge of, either as initial assignment or as a result of failures. We say that the node is a primary holder of these guest data points. A second set of ghost data points contain copies of data held elsewhere in the network. When Polystyrene starts, there are no ghosts, and only one guest data point per node: the node’s original position. At any given time, guest data points are used to derive a node’s actual position, which is then fed to the underlying topology construction protocol. We use a simple projection mechanism, but this is an independent piece of our protocol that can be easily adapted to more complex situation.
Decoupling nodes from data points allows us to implement the migration we need to redistribute nodes around the target shape when catastrophic failures occur. Nodes migrate by periodically exchanging guest data points in order to reach a density-aware tessellation of the data space, i.e. a partition of data points across physical nodes that seeks to maximize locality. After each exchange, each node recomputes the position it provides to the underlying topology construction algorithm, moving in effect around the shape. In other words, nodes migrate by following the migration of their data points.
The result is a decentralized collectively resilient overlay that unlike existing algorithms can maintain its systemic topological properties even in the face of extreme failures. The resulting protocol is further highly scalable, showing a logarithmic convergence time in the size of the system: for instance, a 51,200-node torus converges back to a full torus in only 10 rounds after 50% of the nodes have crashed.
- Task 1 Results:
-
Nédelec, B., Tanke, J., Frey, D., Molli, P., & Mostéfaoui, A. (2017). An adaptive peer-sampling protocol for building networks of browsers. World Wide Web Journal, 1-33.
-
Damien Imbs, Achour Mostéfaoui, Matthieu Perrin, Michel Raynal: Set-Constrained Delivery Broadcast: Definition, Abstraction Power, and Computability Limits. ICDCN 2018: 7:1-7:10
-
Scalable Anti-KNN: Decentralized Computation of k-Furthest-Neighbor Graphs with HyFN Simon Bouget, Yérom-David Bromberg, François Taïani, and Anthony Ventresque, 17th IFIP WG 6.1 International Conference on Distributed Applications and Interoperable Systems (DAIS 2017), Neuchâtel, Switzerland, June, pp. 101-114, 2017, doi:10.1007/978-3-319-59665-5_7
-
Mignon: a Fast Decentralized Content Consumption Estimation in Large-Scale Distributed Systems Stéphane Delbruel, Davide Frey, and François Taïani, 16th IFIP International Conference on Distributed Applications and Interoperable Systems (DAIS 2016), Heraklion, Greece, June, Lecture Notes in Computer Science, volume 9687, pp. 32-46, Springer, 2016 (14p.), doi:10.1007/978-3-319-39577-7_3
-
Filament: A Cohort Construction Service for Decentralized Collaborative Editing Platforms Ariyattu C. Resmi, and François Taïani, 17th IFIP WG 6.1 International Conference on Distributed Applications and Interoperable Systems (DAIS 2017), Neuchâtel, Switzerland, June, pp. 146-160, 2017, doi:10.1007/978-3-319-59665-5_11.
-
Task 2: Quasi-causality and quasi-CRDT
“Given a federated social infrastructure produced by task 1, the objective is to provide probabilistic causal delivery and probabilistic Conflict-free Replicated Data Types (CRDT) structure such as sequences, sets and graphs.”
Major improvement in Sequence Replicated Data types:
- Nédelec, B., Molli, P., Mostefaoui, A., & Desmontils, E. (2013, September). LSEQ: an adaptive structure for sequences in distributed collaborative editing. In Proceedings of the 2013 ACM symposium on Document engineering (pp. 37-46). ACM. (Best Student Paper)
-
Nédelec, B., Molli, P., & Mostéfaoui, A. A scalable sequence encoding for collaborative editing. Journal Concurrency and Computation: Practice and Experience.
-
Nédelec, B., Molli, P., & Mostefaoui, A. (2016, April). Crate: writing stories together with our browsers. In Proceedings of the 25th International Conference Companion on World Wide Web (pp. 231-234). International World Wide Web Conferences Steering Committee

Google Docs made distributed collaborative editors popular. There was more 190M of google drive users in 2015. If such service is really usefull, it has some issues about privacy, economic intelligence and service limitation. Currently, Google is limited to 50 users in real-time editing. In this paper, we aim to build an editor that can scale to millions of simultaneous users. It raises the issue of concurrently editing in real-time a sequence of elements. Real-time constraints force to replicate the shared sequence of characters on each participant. The main problem is to maintain consistency of the massively replicated sequence of element.
Distributed collaborators follow the optimistic replication approach. Given a high number of different participants, each participant has a copy of the sequence of char.
- Each Site freely update his copy locally, with no lock, no communication with any other site.
- Then, it broadcast operations to others. Thank to task 1, we make the hypothesis that all operation eventually arrive.
- Each site integrates remote operations.
The system is correct if it ensures eventual consistency (every site see the same values when system is idle) and preserves intentions (effects observed at generation time are preserved at integration time i.e. if ‘x’ inserted between ‘a’ and ‘b’, then it will be integrated between ‘a’ and ‘b’ whatever concurrent operations). Consistency can be formally defined thanks to Task 3.
Conflict-free replicated data types can be used to build collaborative editors. The general principle is to attach to every element, a unique identifier encoding the position of the element in the sequence as line identified in a BASIC program. The complexities of the sequence type is mainly decided by the function that compute these identifiers.
Imagine you want to type “QWERTY” and have internally of sequence of 32 slots. Each time a character is typed, you have to choose an index to store the character. If user start typing ‘Q’, then a simple function can allow index 1 for ‘Q’, ‘8’ for ‘W’ up to 21 for ‘Y’. But imagine, you started typing ‘Y’ and the function allocated index 1 for ‘Y’, then ‘T’ has to be inserted before, but there is no room. A naive function can just create a new sequence of 32 slots to expend the sequence at this position. But ‘T’ will take the index 1 in this new sequence and ‘R’ is coming. This allocation function will produce identifier with a complexity linear to the size of the sequence. Consequently, the sequence CRDT built on this will not scale in space.
The problem is to craft a function that will create small identifiers whatever the order of creation of the sequence.
The function LSEQ proposed in the paper rely on exponential tree and random allocation. Each time a new allocation space has to be created, the size of this new space is doubled and the strategy of allocation in this space (incremental or decremental) is chosen randomly. We demonstrate that this function allocates identifiers of (log(n))2 in the average case. Consequently, an editor built with LSEQ do not require costly procedures to rebalance identifiers.
Based on this contribution, we plan to demonstrate how it is possible for 1M of people to edit in real-time a shared document. The prototype CRATE allow to test LSEQ in an editor, CRATE relies on the SPRAY gossip algorithm produced by task 1. You can try online.
Major results in causality tracking
-
Probabilistic tracking :
-
Mostéfaoui, A., & Weiss, S. (2017, September). Probabilistic Causal Message Ordering. In International Conference on Parallel Computing Technologies (pp. 315-326). Springer, Cham.
-
-
New way to ensure deterministic causality: Full causality without communicating vector clocks.
-
Brice Nédelec, Pascal Molli and Achour Mostéfaoui. Breaking the Scalability Barrier of Causal Broadcast for Large and Dynamic Systems – Submitted to ICDCS2018.
-
Many distributed protocols and applications rely on causal broadcast to ensure consistency criteria. However, none of causality tracking state-of-the-art approaches scale in large and dynamic systems. This paper presents a new causal broadcast protocol. The proposed protocol outperforms state-of- the-art in size of messages, execution time complexity, and local space complexity. Most importantly, messages piggyback control information the size of which is constant. We prove that for both static and dynamic systems. Consequently, large and dynamic systems can finally afford causal broadcast.
-

Task 3 results: Disorderly Programming
“Given quasi-CRDT data structures produced by task 2, the objective is to deliver a language able to compose Quasi-CRDT and verify properties such as confluence. We aim to integrate Quasi-CRDT into dedicated languages such BloomL and go beyond monotonicity.”
Major results for this task includes a new formal framework able to weak consistency criteria. We expressed and compare all existing criteria and proposed new ones.
- PERRIN, Matthieu, MOSTÉFAOUI, Achour, et JARD, Claude. Brief Announcement: Update Consistency in Partitionable Systems. DISC2014, p. 546.
-
Perrin, M., Mostefaoui, A., & Jard, C. (2015, May). Update consistency for wait-free concurrent objects. In Parallel and Distributed Processing Symposium (IPDPS), 2015 IEEE International (pp. 219-228). IEEE.
-
Matthieu Perrin, Achour Mostéfaoui, Claude Jard:Causal consistency: beyond memory. PPOPP 2016: 26:1-26:12Matthieu Perrin, Matoula Petrolia, Achour Mostéfaoui, Claude Jard, On Composition and Implementation of Sequential Consistency. DISC 2016: 284-297
-
Davide Frey, Achour Mostéfaoui, Matthieu Perrin, Pierre-Louis Roman, François Taïani – Speed for the Elite, Consistency for the Masses: Differentiating Eventual Consistency in Large-Scale Distributed Systems. SRDS 2016
-
Distributed Systems – 1st Edition – Concurrency and consistency – Matthieu Perrin ) ISBN:9781785482267
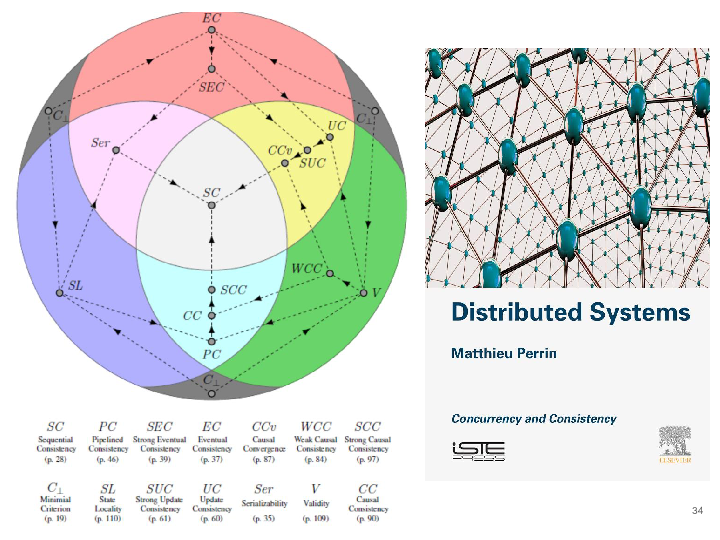
- strong consistency: the object behaves as if there was a unique physical instance of it in the network,
- availability: the methods of the object always return when they are called,
- partition tolerance: separate parts of the network may be unable to communicate with each other for an unbounded amount of time.
- an abstract data type defined by a transition system and which produces a sequential specification
- a consistency criterion that transforms distributed histories (i.e. partially ordered sets of events) into sequential histories in order to match them with the sequential specification.
Task 4: Securing & Usage Control in Federation of Plugs
“Given a federated social infrastructure produced by task 1, the objective is to secure the federation of plugs by monitoring divergence evolution of streams on each node.”
Major results of task 4 concerns what metric can be computed on stream with limited memory. Many metrics can be applied to detect attacks. Major publications are:
- E. Anceaume, and Y. Busnel, “Deviation Estimation between Distributed Data Streams”, Proceddings of the 10th European Dependable Computing Conference (EDCC), May 2014.(pdf)
-
Emmanuelle Anceaume, Yann Busnel. Lightweight Metric Computation for Distributed Massive Data Streams. Dans Transactions on Large-Scale Data- and Knowledge-Centered Systems (TLDKS), LNCS, Springer, 10430(33):1-39, 2017.
-
Nicolò Rivetti, Yann Busnel, Avigdor Gal. FlinkMan: Anomaly Detection in Manufacturing Equipment with Apache Flink: Grand Challenge. Dans 11th ACM International Conference on Distributed Event-Based Systems (DEBS 2017), Barcelone, Espagne, Juin 2017.
-
Nicolò Rivetti, Emmanuelle Anceaume, Yann Busnel, Leonardo Querzoni, Bruno Sericola. Online Scheduling for Shuffle Grouping in Distributed Stream Processing Systems. Dans 17th ACM/IFIP/USENIX 13th International Conference on Middleware (Middleware 2016), Trento, Italie, Décembre 2016.
-
Nicolò Rivetti, Yann Busnel, Leonardo Querzoni. Load-Aware Shedding in Stream Processing Systems. Dans 10th ACM International Conference on Distributed Event-Based Systems (DEBS 2016), Ivine, CA, USA, Juin 2016.
-
Yves Mocquard, Bruno Sericola, and Emmanuelle Anceaume, “Probabilistic Analysis of Counting Protocols in Large-scale Asynchronous and Anonymous Systems“,Proceedings of the 15th IEEE International Symposium on Network Computing and Applications (NCA), 2017.
-
Yves Mocquard, Samantha Robert, Bruno Sericola and Emmanuelle Anceaume, “Analysis of the Propagation Time of a Rumor in Large-scale Distributed Systems“, Proceedings of the 15th IEEE International Symposium on Network Computing and Applications (NCA) 2016. Best student paper
-
Yves Mocquard, Emmanuelle Anceaume, and Bruno Sericola, “Optimal Proportion Computation with Population Protocols“, Proceedings of the 15th IEEE International Symposium on Network Computing and Applications (NCA), 2016.

Performance of many complex monitoring applications, including Internet monitoring applications, data mining, sensors networks, network intrusion/anomalies detection applications, depend on the detection of correlated events. For instance, detecting correlated network anomalies should drastically reduce the number of false positive or negative alerts that networks operators have to currently face when using network management tools such as SNMP or NetFlow. Indeed, to cope with the complexity and the amount of raw data, current network management tools analyze their input streams in isolation. Diagnosing flooding attacks through the detection of correlated flows should improve intrusions detection tools.
The point is that, in all these monitoring applications, data streams arrive at nodes in a very high rate and may contain up to several billions of data items per day. Thus computing statistics with traditional methods is unpractical due to constraints on both available processing capacity, and memory. The problem tackled in this paper is the on-line estimation of data streams correlation. More precisely, we propose a distributed algorithm that approximates with guaranteed error bounds in a single pass the linear relation between massive distributed sequences of data.
Two main approaches exist to monitor in real time massive data streams. The first one consists in regularly sampling the input streams so that only a limited amount of data items is locally kept. This allows to exactly compute functions on these samples. However, accuracy of this computation with respect to the stream in its entirety fully depends on the volume of data items that has been sampled and their order in the stream. Furthermore, an adversary may easily take advantage of the sampling policy to hide its attacks among data items that are not sampled, or in a way that prevents its “malicious” data items from being correlated.
In contrast, the streaming approach consists in scanning each piece of data of the input stream on the fly, and in locally keeping only compact synopses or sketches that contain the most important information about these data. This approach enables to derive some data streams statistics with guaranteed error bounds without making any assumptions on the order in which data items are received at nodes. Most of the research done so far with this approach has focused on computing functions or statistics measures with very small error using sublinear space in the item domain size.
On the other hand, very few works have tackled the distributed streaming model, also called the functional monitoring problem, which combines features of both the streaming model and communication complexity models. As in the streaming model, the input data is read on the fly, and processed with a minimum workspace and time.
In the communication complexity model, each node receives an input data stream, performs some local computation, and communicates only with a coordinator who wishes to continuously compute or estimate a given function of the union of all the input streams. The challenging issue in this model is for the coordinator to compute the given function by minimizing the number of communicated bits.
In this task, we go a step further by studying the dispersion matrix of distributed streams.
Specifically, we have proposed a novel metric that allows to approximate in real time the correlation between distributed and massive streams. This metric, called the sketch* metric, allows us to quantify how observed data items change together, and in which proportion. We are convinced that such a network-wide traffic monitoring tool should allow monitoring applications to get significant information on the traffic behavior changes to subsequently inform more detailed detection tools on where DDoS attacks are currently active.
Task 5 : Usage Control
“Given a federated social infrastructure produced by task 1, the objective is to attach usage control policies to each data retrieved from the federation and to ensure usage policies at plug level.”
Major results concern how it is possible to recompose queries from traces in logs. This allow to understand how distributed data are used.
-
Nassopoulos, G., Serrano-Alvarado, P., Molli, P., & Desmontils, E. (2016, September). FETA: Federated QuEry TrAcking for Linked Data. In International Conference on Database and Expert Systems Applications (pp. 303-312). Springer International Publishing.
-
Desmontils, E., Serrano-Alvarado, P., & Molli, P. (2017, October). SWEEP: a Streaming Web Service to Deduce Basic Graph Patterns from Triple Pattern Fragments. In 16th International Semantic Web Conference.
-
Valeria Soto-Mendoza, Patricia Serrano-Alvarado, Emmanuel Desmontils, José-Antonio García-Macías. “Policies Composition Based on Data Usage Context “. In International Workshop on Consuming Linked Data (COLD) at ISWC, 12 pages, Bethlehem, Pennsylvania, United States, 12 October 2015.
Following the principles of Linked Data (LD), data providers are producing thousands of interlinked datasets in multiple domains including life science, government, social networking, media and publications. Federated query engines allow data consumers to query several datasets through a federation of SPARQL endpoints. However, data providers just receive subqueries resulting from the decomposition of the original federated query. Consequently, they do not know how their data are crossed with other datasets of the federation. In this paper, we propose FETA, a Federated quEry TrAcking system for LD. We consider that data providers collaborate by sharing their query logs. Then, from a fed-erated log, FETA infers Basic Graph Patterns (BGPs) containing joined triple patterns, executed among endpoints. We experimented FETA with logs produced by FedBench queries executed with Anapsid and FedX federated query engines. Experiments show that FETA is able to infer BGPs of joined triple patterns with a good precision and recall.
Conclusion & Perspectives
Descent achieved important results:
- Task 1 on federated social infrastructure demonstrated how it possible to establish reliable communications adapting to the number of participants
- Task 2 on quasi-CRDT presented how it is possible to build CRDT that fully scales, breaking the barrier of causality.
- Task 3 reformalized all weak consistency criteria, making them comparable and proposed new ones.
- Task 4 proposed stream based approaches to detect malicious behaviors in a federation. The different contributions are compatible with limited memory and low CPU capacities of plugs computers.
- Task 5 proposed an original approach, able to recompose distributed queries and then to detect how scattered data are used.
As perspectives:
- These works are continuing through the project “Web of Browsers” in order to disseminate results for local companies (APIZEE).
- Works on usage control are continuing through CIFRE contract with company OpenDataSoft.
- Works with browsers are continuing within the project ANR “O’Browser“.