
Interactive Communication (INTERCOM):
Massive random access to subsets of compressed correlated data
This project aims to develop novel compression techniques allowing massive random access to large databases. Indeed, we consider a database that is so large that, to be stored on a single server, the data have to be compressed efficiently, meaning that the redundancy/correlation between the data have to be exploited. The dataset is then stored on a server and made available to users that may want to access only a subset of the data. Such a request for a subset of the data is indeed random, since the choice of the subset is user-dependent. Finally, massive requests are made, meaning that, upon request, the server can only perform low complexity operations (such as bit extraction but no decompression/compression).
Algorithms for two emerging applications of this problem will be developed: Free-viewpoint Television (FTV) and massive requests to a database collecting data from a large-scale sensor network (such as Smart Cities).
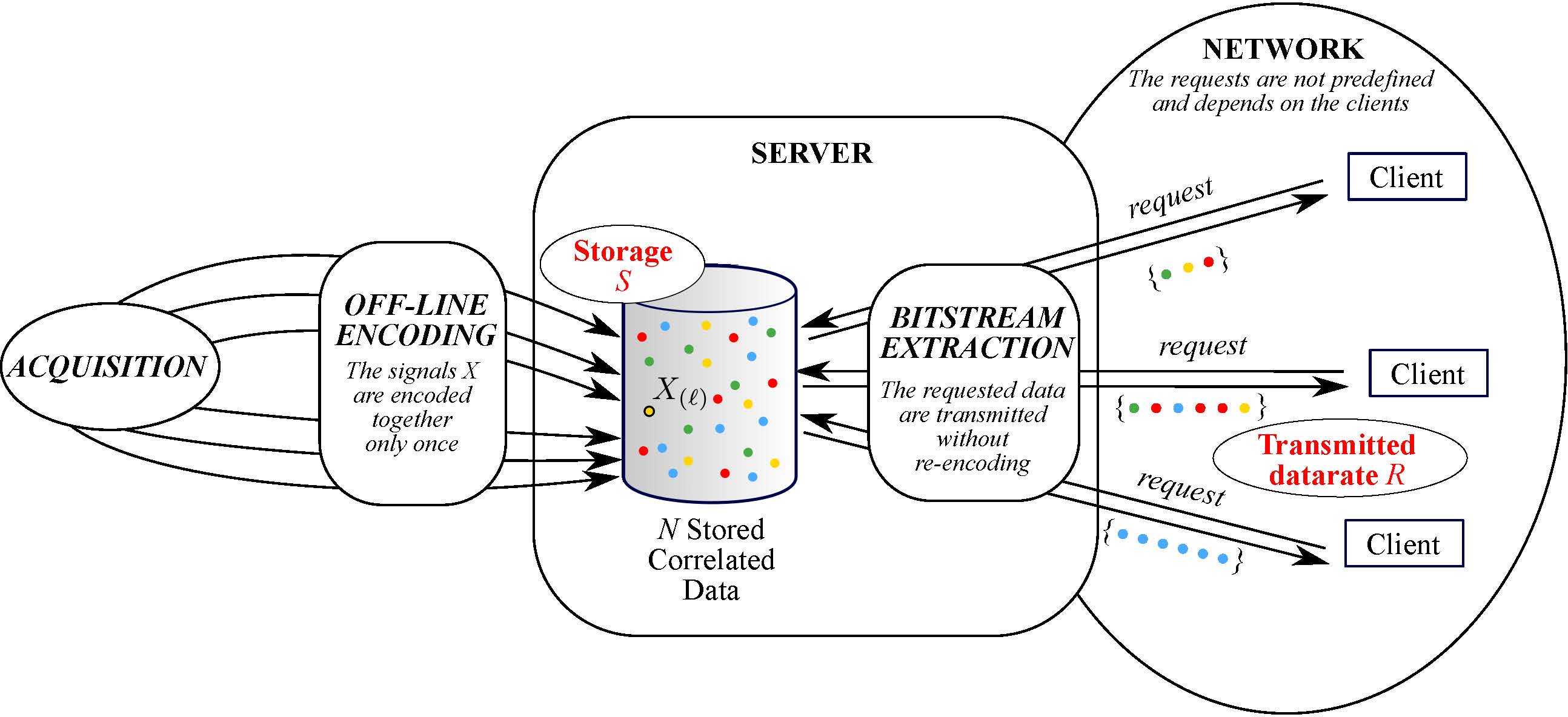
Random access to a database: the user can choose any subset of the compressed correlated data.
Project leader: Aline Roumy
The consortium involves the following people and teams:
- Inria, Sirocco team: Aline Roumy, Thomas Maugey
- LabSTICC, Télécom Bretagne, Signal & Communications Department: Elsa Dupraz, Karine Amis
- Inria, i4S team: Jean Dumoulin
- External partners:
- Univ. Paris Saclay: Michel Kieffer
- Univ. Cote Azur: Frédéric Payan
- EPFL: Roberto Gerson De Albuquerque Azevedo and Pascal Frossard