
To conclude this collaborative project between Lab-STICC (Brest, France), LS2N (Nantes, France) and Crossing (Adelaide, Australia), the results were summed up in a paper accepted for presentation at IEEE COMPSAC 2026, the IEEE Computer Society’s flagship conference on Computers, Software, and Applications.
The associated publication is available here.
Publications
6 articles were presented in international conferences and are listed here.
PhD and Master students
3 PhD students collaborated to the project:
– Lucas Grativol Ribeiro (“Neural network compression in the context of federated learning and edge devices”, 05/12/2024),
– Hugo Le Blevec (“Joint design of deep neural networks and FPGA dataflow architectures for semantic segmentation in autonomous vehicles”, 06/12/2024),
– Ismail Amessegher (“Joint design of compression techniques for deep neural networks and low-energy processors for event-based computer vision”, to be held in October 2026).
2 Master students were also involved:
– Clémence Liard (“Design of a synthetic event-based dataset for machine learning”, 2023), between IMT Atlantique in Brest, France and Crossing Laboratory in Adelaide, Australia.
– Ala Souissi (“UAV Object Tracking based on Deep Reinforcement Learning”, 2024)
Contributions of the project
Summary
The works performed in the context of the LEASARD project demonstrated the importance of jointly taking into account hardware, software and algorithmic aspects in the development of drones endowed with state-of-the-art AI capabilities. Event-cameras offer a number of advantages for UAVs that operate in adverse environments, likewise, conventional cameras can capture information that is complementary. RGB alone is generally superior than event images for scene perception while on the other hand event data allow for more reactive drone control and maneuvering. The fact that RGB-based DNN are generally superior for scene perception can be partly attributed to the scarcity of event-camera data benchmarks,
most of which have been collected by ground vehicles in urban scenes, as opposed to abundant RGB datasets that are available from diverse domains. Leveraging the full power of event-cameras therefore requires additional sources of training data,in parallel with the adoption of transfer learning algorithms.
We designed a low-latency object detection model based on YOLO, LoLa-YOLO, fitted to search-and- rescue missions, and able to process data coming from RGB and event cameras. To our knowledge, this is the first low-complexity YOLO model destined for detection in SAR scenarios using event or RGB cameras. We also propose a low-latency implementation on FPGA on board drones, achieving accurate detection in less than 20ms. Through a series of tests using a prototype drone, we highlight the features of the model and processing core that favor drone reactivity and operational autonomy.
Learning with appropriate datasets
The question of the datasets
What datasets are available for event cameras on UAVs? We do not know any dataset to train event-based DNNs that could improve the navigation autonomy of UAVs for SAR missions. There is the drone racing dataset from the University of Zürich, which is limited to indoor and specific to drone racing. There are many native event camera datasets, mainly for automotive applications, such as DDD20, Prophesee 1MEGAPIXEL, and DSEC. RGB-based UAV datasets exist, such as VisDrone, UAVDT, and SARD, and can be converted into event datasets using tools such as v2e. However, these datasets are not suitable for training deep neural networks (DNNs) for autonomous navigation of UAVs in different environments, such as forests, caves, and destroyed buildings, which are expected during SAR missions.
Simulating Aerial Event-based Environment: Application to Car Detection, presented at ERF’24.
We presented at the European Robotics Forum 2024 our framework to simulate an aerial event-based environment, which can be used to train and evaluate artificial vision tasks, such as detection, in diverse conditions.
To build versatile datasets on demand to train deep neural networks (DNNs) for event cameras and UAVs, several tools can be used. Airsim provides a complete simulation environment allowing different scenarios in realistic conditions with diverse light conditions, and refined graphics thanks to Unreal Engine. Coupled with v2e, it produces realistic and rich event streams that may be provided by an event camera mounted on a UAV. This allows DNN models to be tested, but not yet to be trained. To do so, we used UnrealGT to get a ground truth. We validated this framework to train an event-based YOLOv7 model.
More details are provided in our paper:
Ismail Amessegher, Hajer Fradi, Clémence Liard, Jean-Philippe Diguet, Panagiotis Papadakis, and Matthieu Arzel. Simulating Aerial Event-based Environment: Application to Car Detection. European Robotics Forum 2024, Mar 2024, Rimini, Italy. ⟨hal-04497648⟩

Event-based control
UAV Object Tracking based on Deep Reinforcement Learning
We investigated how to design an efficient low-latency controller that would allow a UAV to follow a leader in full autonomy. The proposed tracking controller is designed to respond to visual feedback from the mounted event sensor, adjusting the drone movements to follow the target. To leverage the full motion capabilities of a quadrotor and the unique properties of event sensors, we propose an end-to-end deep-reinforcement learning (DRL) framework that maps raw sensor data from event streams directly to control actions for the UAV. To learn an optimal policy under highly variable and challenging conditions, we opt for a simulation environment (Airsim) with domain randomization for effective transfer to real-world environments, as forests, caves, or rooms with complex patterns.
We demonstrate the effectiveness of our approach through experiments in challenging scenarios, including fast-moving targets and changing lighting conditions, which result in improved generalization capabilities.
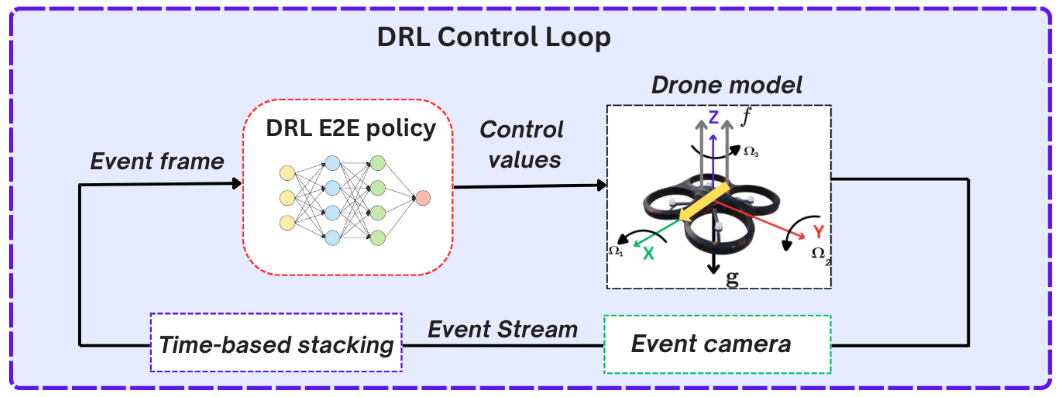

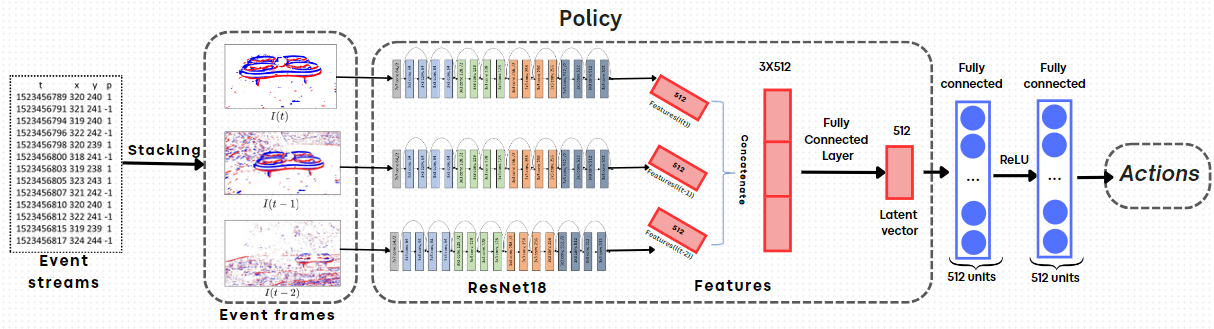
This work was submitted for publication and is available here: ⟨hal-04714734⟩
Event-RGB sensor fusion
How and why to combine event and RGB cameras?
Real-time vision applications such as object detection for autonomous navigation have recently witnessed the emergence of neuromorphic or event cameras, thanks to their high dynamic range, high temporal resolution and low latency. In this work, our objective is to leverage the distinctive properties of asynchronous events and static texture information of conventional frames. To handle that, asynchronous events are first transformed into a 2D spatial grid representation, which is carefully selected to harness the high temporal resolution of event streams and align with conventional image-based vision. Via a joint detection framework, detections from both RGB and event modalities are fused by probabilistically combining scores and bounding boxes. The superiority of the proposed method is demonstrated over concurrent Event-RGB fusion methods on DSEC-MOD and PKU-DDD17 datasets by a significant margin.
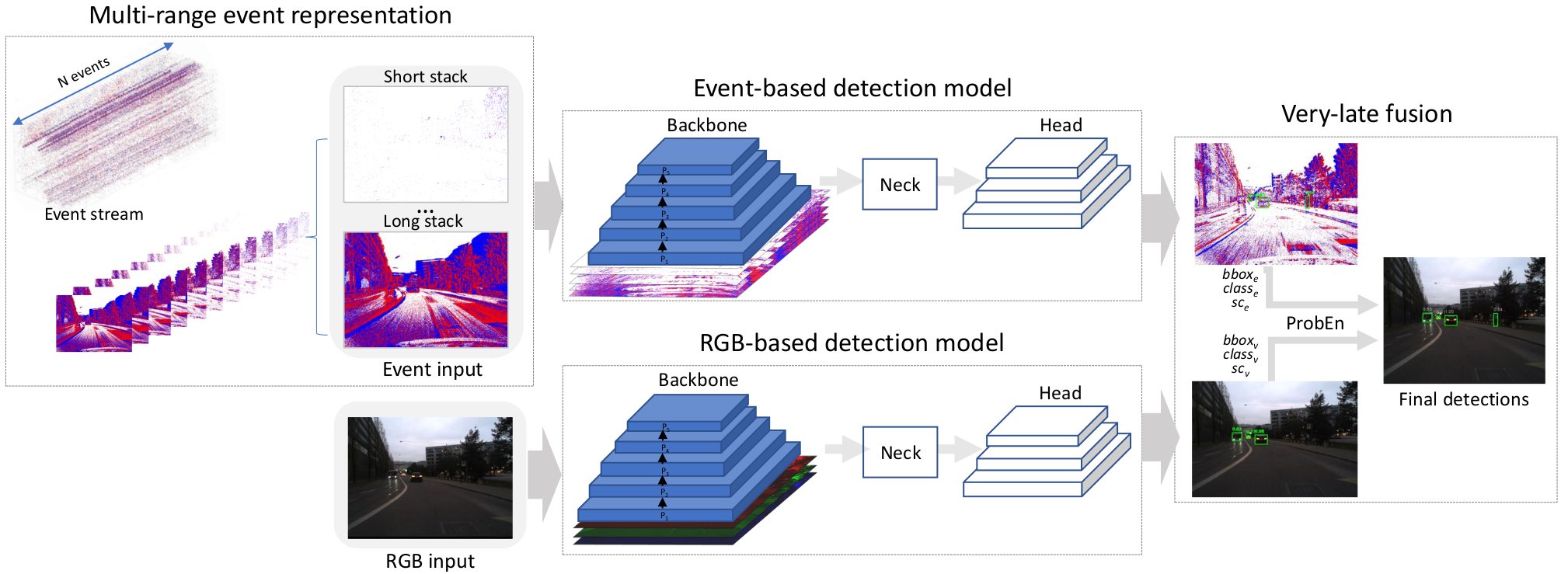
This work was accepted for publication at the IEEE International Conference on Robotic Computing 2024, and is available here: ⟨hal-04746439⟩.
DNNs on FPGA
Rich RGB semantic segmentation on FPGA
Semantic segmentation is a complex task that benefited from major improvements thanks to recent advances in machine learning and more specifically in DNNs. It allows an accurate understanding of complex environments, making technology like autonomous vehicles possible. Our first intuition was that RGB cameras would be required to have enough information to run this task with acceptable accuracy and that the models would be too complex to run with a low latency. For instance, the time available to avoid an obstacle while moving at 20m/s is around 50ms.
We thought that it would be fairly difficult to achieve such a low latency with semantic segmentation. However, we thought that it would nicely complement detection, which could benefit from simpler DNNs and the low latency of event-based vision. So, we decided to evaluate RGB semantic segmentation and event-based detection (detailed in the next section).
Datasets like Cityscapes are available to train semantic segmentation models for autonomous car driving and are useful to first benchmark what can be achieved with efficient implementations of DNNs on FPGAs. These hardware targets have proven to be excellent for deploying highly parallel, low-latency and low-power DNN architectures for embedded and cloud applications. Many FPGA implementations use recursive architectures based on Deep Processing Units (DPUs) for fast and resource-efficient solutions which usually come at the cost of a higher latency. On the other hand, pipelined dataflow architectures have the potential to offer scalable, low-latency implementations. In this work, we have explored implementing a semantic segmentation network as a pipelined architecture and evaluated the achievable performances. Our model, a convolutional encoder-decoder based on U-Net, achieves 62.9 % mIoU on the Cityscapes dataset with a 4-bit integer quantization. Once deployed on the Xilinx Alveo U250 FPGA board, the implemented neural network architecture is able to output close to 23 images per second with 44 ms latency per input. The code of this work is open-source and was released publicly. This work was also published at the IEEE 30th International Conference on Electronics, Circuits and Systems, Dec 2023, Istanbul, Turkey ⟨10.1109/ICECS58634.2023.10382715⟩ ⟨hal-04262138v2⟩.
With such results on a datacenter-class board, the aim of analyzing the environment with a latency compliant with a speed of 20m/s was achieved. However, this model is still too complex (14M parameters) to be embedded on a smaller FPGA board fitting a UAV.
Therefore, we proposed a second version based on ENet with only 350k parameters achieving 70.3 % mIoU on the Cityscapes dataset with 4-bit integers (inputs : 512X256), 226 FPS with 4.2 ms latency per input on an AMD ZU19EG (embedded-class board), and 6.8W peak power consumption (measured).
So, our first intuition that semantic segmentation was too complex to be compliant with low-latency event streams was wrong. But would it be beneficial from an information point of view? Could event cameras bring enough information for an accurate semantic segmentation? These questions are still open.

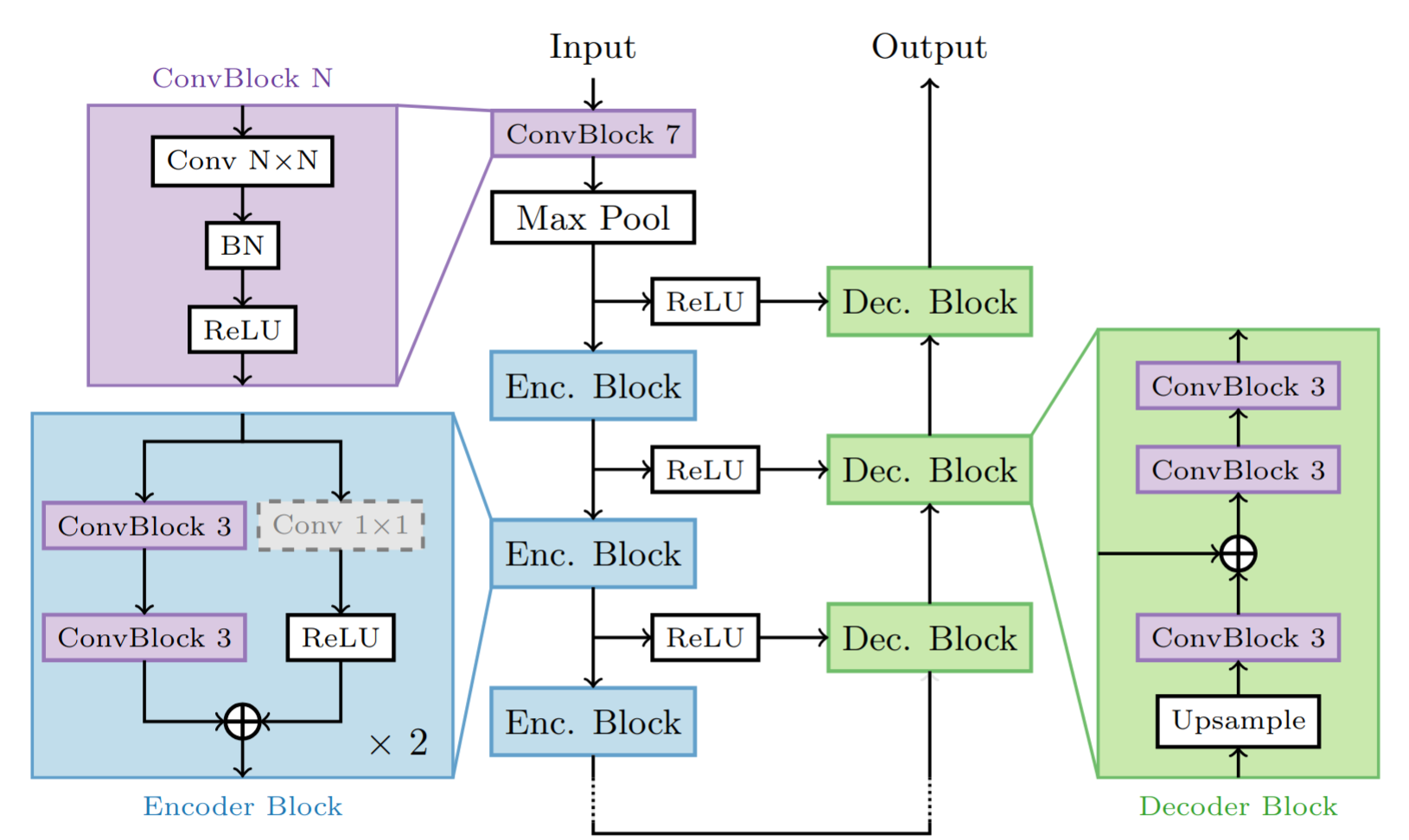
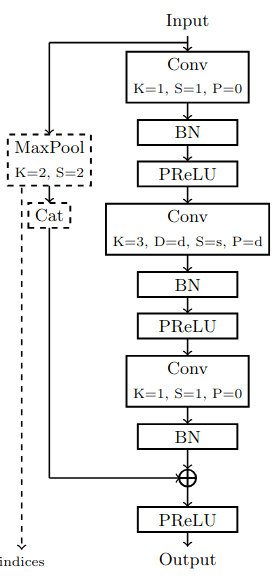
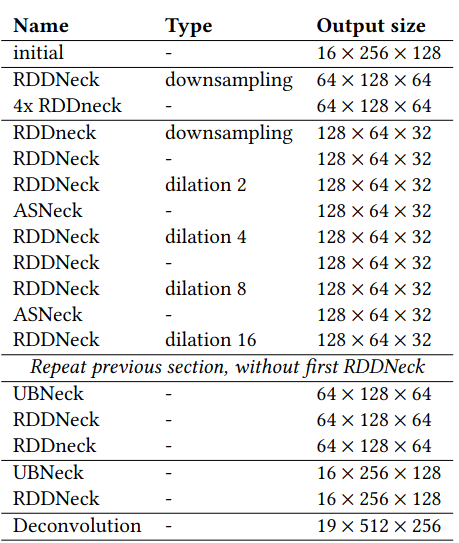
puts and 19 classes as in the Cityscapes dataset. Table adapted
from original paper on Enet.
Our second Enet-based model to run semantic sementation on FPGA, with less resources and a reduced latency.
Low-latency event-based detection on FPGA
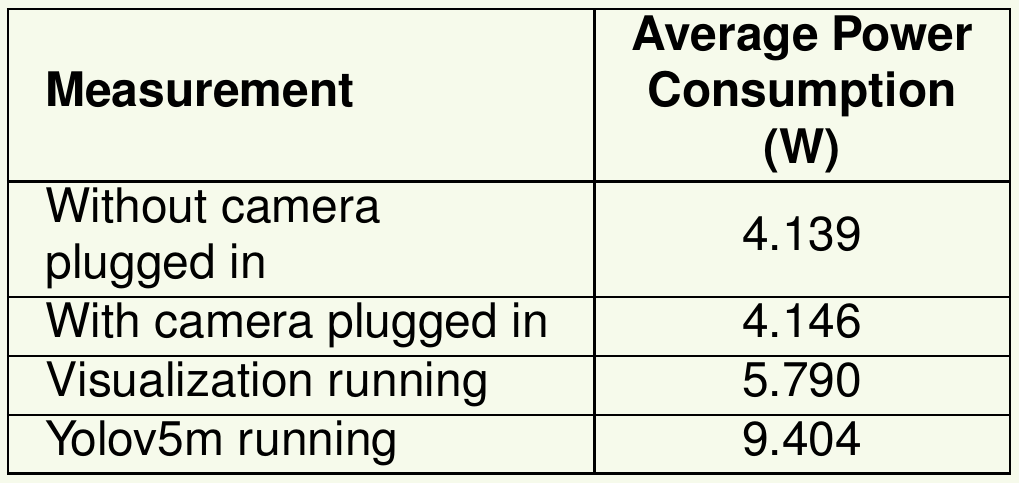
To detect obstacles in front of the UAV, we considered YOLO as a candidate to evaluate. Specifically, YOLOv5m, which has 21 million parameters, was tested on the Jetson Orin Nano. This model was trained on the DSEC-MOD dataset and quantized to 8 bits. However, it has an inference time of at least 70 milliseconds, resulting in a maximum frame rate of 14 frames per second, making it not the best choice for real-world applications.
Alternatively, TinyYOLOv3, which has 8 million parameters and 13 convolutional layers, was tested on an FPGA. Using FINN and BREVITAS to quantize on 8 bits and map the model to hardware layers, the first results showed a frame rate of 18 frames per second with a latency of 50 milliseconds at 100MHz on a modest Pynq Z1.
We developed LoLa-YOLO a Low-Latency detection model, based on evolutions of YOLO optimized for FPGA implementation. To our knowledge, this is the first low-complexity YOLO model destined for detection in SAR scenarios using event or RGB cameras. Other low-complexity YOLO models such as LPYOLO [20] have been proposed, but they are suited for tasks such as face detection and are not trained on event-based datasets. Reported prototype measurements confirm the low latency and low power consumption of our solution while via indoor tests with a UAV-mounted event camera flying over miniaturized objects, we demonstrated the potential of LoLa-YOLO despite the fact that it was trained on automotive and city-scape datasets.

YOLOv5 quantized on 8bits and trained on the DSEC-MOD dataset

This work was published at SSRR 2025.
UAV platform
What about the power consumption of the whole system?

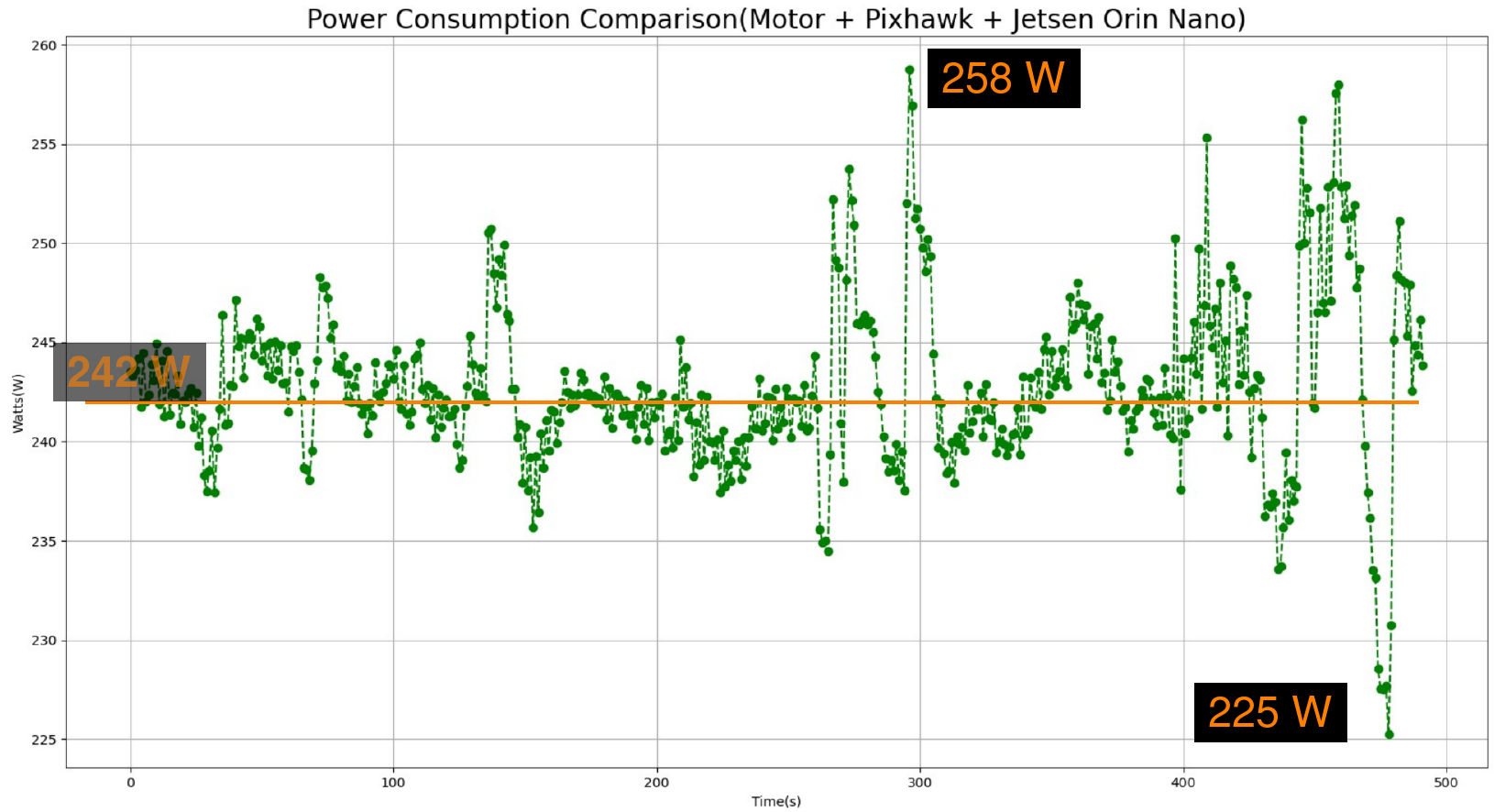
We designed a UAV prototype based on the combination of a Pixhawk board, a NVidia Jetson Orin Nano and an event-camera (DVXplorer Mini by Inivation).
During a static flight, the power consumption of the whole system, without any DNN model running, was measured. 242W are required by the motors, the flight controler (Pixhawk) and the on-board computer (Jetson Orin Nano, power mode set to 15W max.). After measuring the power consumption of the event camera and of the Jetson board running the YOLOV5m model, we can conclude that the few watts consumed by the artificial vision remain not significant when compared to the 242W required by a static flight.
The few Watts used by on-bard artificial intelligence are worth the cost if they allow to reduce the power budget associated with the motors!
For instance, if we can learn to avoid obstacles with the best trajectory as shown in the video below, then less energy will be spent to fly and more will be used to inspect the environment in Search-An-Rescue missions.

This work was published at SSRR 2025.