
Optimization of data movements between chips
Memory bandwidth is known to be a performance bottleneck for FPGA accelerators, especially when they deal with large multi-dimensional data-sets. A large body of work focuses on reducing of off-chip transfers, but few authors try to improve the efficiency of transfers. The later issue is addressed by proposing (i) a compiler-based approach to accelerator’s data layout to maximize contiguous access to off-chip memory, and (ii) data packing and runtime compression techniques that take advantage of this layout to further improve memory performance. We show that our approach can decrease the I/O cycles up to 7× compared to un-optimized memory accesses.
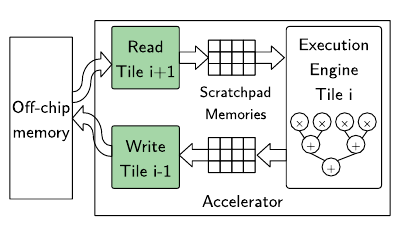
The figure above shows the macro-pipeline structure supported by HLS tools through manual code annotation. The goal of this work is to propose a source level compiler optimisation to (i) reorganize data in memory to enable contiguous burst access and (ii) further improve bandwidth utilization through packing and compression.
Optimization of data movements inside the computing chip
The optimization of data movements inside the computing chip can be studied from two complementary points of view.
Exploration of customizable interconnects and organizations
This architectural proposition is to explore customizable interconnect topologies to build dataflow stream processing architectures that match the shape of the application.
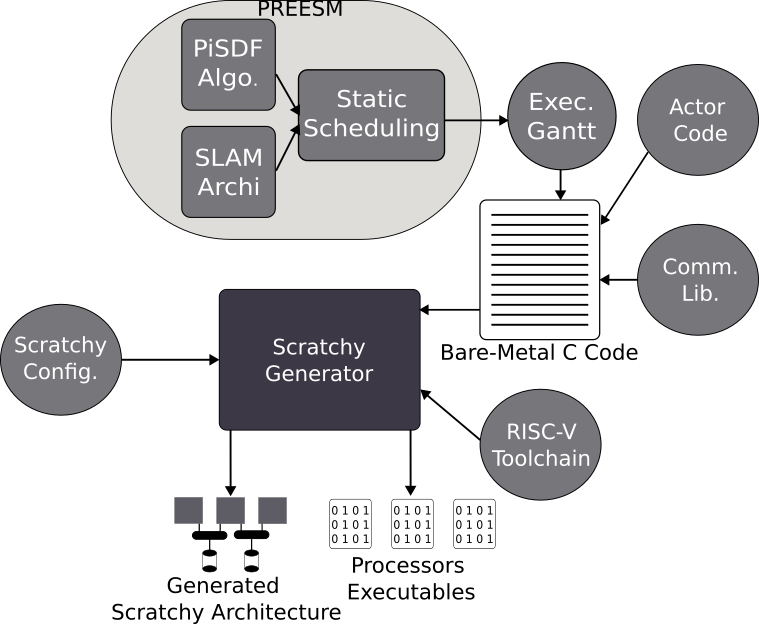
The figure above shows the design flow proposed in Scratchy. Scratchy is a class of software-managed communication multi-RISC-V adaptable architectures designed for streaming applications. Scratchy uses scratchpad memories and offers customizable interconnect topology and storage options to optimize synchronization and communication time. The custom interconnects can provide many topologies with arbitrary numbers of busses and scratchpad memories. A middleware for Synchronous DataFlow (SDF) applications is provided through the LiteX and PREESM tools for static scheduling. This work demonstrates Scratchy capabilities through a design space exploration test case that aims to derive an efficient multicore topology for executing two SDF-described applications. Additionally, customizing the communication for a 3-core Scratchy only adds 2% resource overhead. The implementations presented in the article [1] were developed using a small Intel MAX10 FPGA with only 205 kB of BRAM. Among the architectures implemented, the most resource-intensive takes less than 5 minutes to synthesize.
Computing-in-network
A very recent and promising approach is to compute the data on its way in the network.
Programmability
Starting from a dataflow model of computation, it is possible to automatically detect and derive the actors candidates for computing in network. An ongoing work focuses on how to automatically transform an SDF graph into a PAFG. The PAFG features allow to map the corresponding actors onto the computing routers.