
Big Data Analystics for Unstructured Clinical Data
Context
Health Big Data (HBD) is more than just a very large amount of data or a large number of data sources. The data collected or produced during the clinical care process can be exploited at different levels and across different domains, especially concerning questions related to clinical and translational research. To leverage these big, heterogeneous, sensitive and multi-domain clinical data, new infrastructures are arising in most of the academic hospitals, which are intended to integrate, reuse and share data for research.
Yet, a well-known challenge for secondary use of HBD is that much of detailed patient information is embedded in narrative text, mostly stored as unstructured data. The lack of efficient Natural Language Processing (NLP) resources dedicated to clinical narratives, especially for French, leads to the development of ad-hoc NLP tools with limited targeted purposes. Moreover, the scalability and real-time issues are rarely taken into account for these possibly costly NLP tools, which make them inappropriate in real-world scenarios.
Some other today’s challenges when reusing Health data are still not resolved: data quality assessment for research purposes, scalability issues when integrating heterogeneous HBD or patient data privacy and data protection. These barriers are completely interwoven with unstructured data reuse and thus constitute an overall issue which must be addressed globally.
Our project
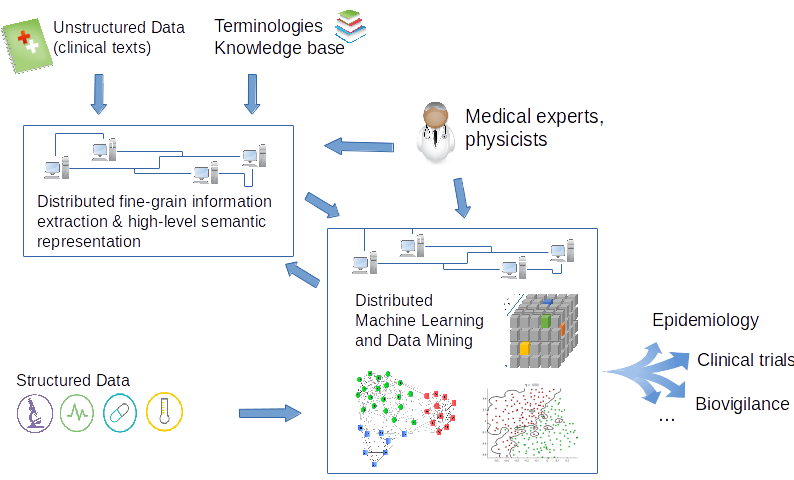
The BigClin project thus proposes to address the essential need to leverage the above barriers when reusing unstructured clinical data at a large scale:1) We propose to develop new clinical records representation relying on fine-grained semantic annotation thanks to new NLP tools dedicated to French clinical narratives.
2) Since, the aim is to efficiently map this added semantic information to existing structured data to be further analyzed in a Big data infrastructure, the project also addresses distributed systems issues: scalability, management of uncertain data and privacy, stream processing at runtime…
In this project, we will demonstrate how clinical research might leverage NLP, information retrieval (IR) and automatic reasoning methods in order to address different use cases. The specific objectives are:
-To develop methods of information extraction and indexing dedicated to clinical texts;
-To exploit data mining techniques to handle conjointly the generated representation of the unstructured information of the clinical records and the existing structured clinical information;
– To develop distributed methods to ensure both the scalability and the online processing of these NLP/IR and data mining techniques;
– To evaluate the added value of these methods in several real clinical data and on real use-cases, including epidemilology and pharmaco-vigilance, clinical practice assessment and health care quality research, clinical trials.
Partners
Inserm/LTSI (HBD team), CNRS-IRISA (LinkMedia, Cidre & Dionysos teams).
External collaborator: CNRS-STL