
Activity Report March 2018
William Dedzoe, Jean Hany, Albert Benveniste
Status of the deployments to date (March 2018)
The service is now stable in its concept and format. To describe what the service is the best is to reproduce here the primer that sits on the header of the service itself:
What is LookinLabs4HAL?
LookinLabs for HAL-archives is more than a search tool. It allows you to find, among teams/individuals/publications, those best matching your query (short desscription of a scientific topic, as keywords or text). The tool exploits, as data, HAL-archives. No ontology is used. No data need to be manually entered (besides the users’ queries). The tool uses Elasticsearch as its core algorithm. This means that the matching is based on a distance between the query and the set of data attached, in HAL, to each team/individual/publication. Ranking is performed accordingly. Explanations are given for each returned item. Correlation graphs are given, allowing to navigate through teams or individuals that share common interests (they may or may not be co-authors). Results can be stored in the basket and sent to your favorite email.
How to use LookinLabs ?
As a simplest use, just enter your query. For example, if you enter network security, the tool will look for best matching with respect to `network’, `security’, and the digram `network-security’, with a bias in favor of the latter. If you really mean the digram only, you can specify this by adding quotes: “network security”. Then, the tool will look for the digram only and stop in case of the matching succeeds. In case of failure, quotes are removed and the tool operates in its basic mode.
The tool claims to perform semantic matching. If, however, by network security, you have in mind the whole domain with its bench of associated keywords, this implicit context is not known by LookinLabs since LookinLabs makes no use of any kind of ontology in its current release. You can still benefit from sort of an adaptive ontology by using the tool stepwise as follows:
1. Enter your query;
2. Read the abstracts of the very first publications returned by the tool and select the one(s) you find best for describing your topic;
3. Copy this abstract and enter it as your refined query.
This yields a rich query that will act as an ontology by enhancing your topic with all the words of the abstract.
The service is adapted to different domains or laboratories, by taking advantage of the administrative data that are made available by each domain or lab. In the following, we describe how the service is adapted for Inria and for the different labs that are partners of CominLabs. For each case, we describe the additional work requested for such an adaptation.
Inria
LookinLabs4HALInria is the richest adaptation of LookinLabs4HAL by taking advantage of the following facts and data, that are unique to Inria:
- Inria is structured into teams with no other structuration such as departments, etc. This makes it easier to return responses in terms of both individuals and teams.
- The web activity report of all Inria teams (nickname Raweb) provides a number of “certified” administrative information regarding the persons. For each Inria team, the list of members is given and the name of each member is guaranteed unique, with no variation throughout the report (this is checked by the web tool at the creation of the report). Each author of a HAL publication of the considered team is matched against the Raweb member list. This allows getting rid of the variations in the names.
- The BASTRI web site maintains the list of Inria teams together with a history of them (parent-child relations between teams, if any). This information is used by LookinLabs for pointing to a recent team, which otherwise would not appear in the responses due to a too small number of publications. Typically, a parent team is found by the tool and BASTRI is used to complement this information with the child recent team.
In addition, since both Raweb and BASTRI are maintained and updated by Inria, the link between Raweb, BASTRI, and LookinLabs allows for an automatic update of the administrative data. Updates are on-the-fly for BASTRI and annual for Raweb. In all cases, automatic annual updates of the administrative data can be established for LookinLabs.
This makes LookinLabs4HALInria fully automatic, with no need for manual data loading.
In relation with the DSI (Information Service Department of Inria), a wiki has been developed that would allow to hand over to Inria DSI the management of LookinLabs. The content of this wiki as well as the evaluation of the software development methodology are almost completed by the DSI.
Other labs partners of CominLabs
For other labs partners of CominLabs, who are not part of Inria, we cannot use the above complementary administrative data. Difficulties, therefore, arise regarding variations in the names of the authors and, mainly, the parent-child links between the different teams of the considered lab. Also, former researchers, who have left the lab, are no longer visible. This results in a slight degradation in performance of the service regarding individuals, and a stronger degradation regarding teams. In turn, the labs are much smaller than Inria and, therefore, have a much smaller number of teams.
Dealing with labs of small or modest size
One specific difficulty arises when we deploy LookinLabs for a particular lab. The population of the lab is not large in general (from less than 100 to a few hundreds), which can be a problem for data mining algorithms. Three strategies can be considered when performing the first phase of the processing, namely the indexing of the publications data base:
- Apply the data mining algorithms to the bibliographical data base collecting all the publications of the lab only.
- Form the union of the populations of all labs of CominLabs at hand (including Inria in its whole, about 100,000 publications) and index it. This way, each publication is characterized by a set of tokens (keywords) that best identifies it in the context of the whole, large, data base. Then, a query is best matched to the individuals or teams that belong to the considered lab — other individuals or teams are filtered out.
- Same, but take all publications of HAL, covering all topics (about 1,300,000 publications).
We chosed the first strategy because the response time was more than twice as long when we request data using strategies 2 or 3 and results returned by the three strategies were almost the same. The same issue arises when constructing the topics characterizing an individual or a team from a given lab. The same three strategies can be considered, with the same conclusions.
Making LookinLabs fully automatic
So far LookinLabs in its current form is not fully automatic, except for Inria. The reason is that the administrative information (correct list of individuals and teams) is generally not stored in a formal data base with clear API. The considered information was delivered to us manually, so we expect updates to be done manually. We believe this is a serious obstacle to the long term maintenance of the service. We believe it is essential to have it fully automatic (besides the maintenance of the software itself). We consider this lack of a formalized administrative information data base to be important for a successful deployment of LookinLabs. We are also quite sure it can serve many other purposes for the lab.
Status of the deployment (march 2018)
LookinLabs4HAL is deployed for the laboratories partners of CominLab who have accepted the following minimal set of conditions:
- Willingness to provide the list of lab members and teams;
- To have a person responsible for interacting with LookinLabs development team.
The links to the services deployed for the different labs are :
- Inria: https://lookinlabs4halinria.cominlabs.u-bretagneloire.fr
- LS2N: https://lookinlabs4halls2n.cominlabs.u-bretagneloire.fr
- Foton: https://lookinlabs4halfoton.cominlabs.u-bretagneloire.fr
- LTSI : https://lookinlabs4halltsi.cominlabs.u-bretagneloire.fr
- IETR: https://lookinlabs4halietr.cominlabs.u-bretagneloire.fr
- IMT/LabSticc: https://lookinlabs4halsticc.cominlabs.u-bretagneloire.fr
Do not hesitate trying these services!
Next steps
Next steps concern both usage and technology.
Further developing the use of LookinLabs
The second task concerns awareness, within the labs partners of CominLabs. This is something we are currently discussing with the heads of these labs and we hope to find new means to improve the situation.
Regarding Inria, one favorable point is the fact that a researcher (Peter Sturm) has been appointed by Inria head to coordinate the different efforts related to Inria scientific information system and to create synergies. This includes all actions related to HAL, including LookinLabs. We are thus in periodic contact with Peter. Now, awareness is far from trivial since Inria is a much bigger institution with over 3000 people in its set of associated teams (not all of them being Inria employees). The service is already deployed but remains mostly unknown to the researchers, not to mention the general public. Improving awareness is thus a task in itself. We are discussing with representatives of the direction of Inria about the following action items:
- making LookinLabs accessible on the intranet and announcing it to the population of all researchers via a note in the Inria Newsletter;
- including LookinLabs as a service visible from the forthcoming Inria web site (this web site will be significantly modified in the near future).
Clearly, the second option would be a much bigger step forward and we are currently struggling at obtaining it.
Issues related to the technology
For some individuals or teams, different areas are covered (this is, for instance, the case for Albert Benveniste himself, with activities in signal processing, vibration mechanics, embedded systems design and programming, and web services). Currently, the topics characterizing such individuals or teams are organized as an ordered, but otherwise flat list, where topics related to different areas are interleaved. It would be desirable to structure topics according to semantic clusters instead. This is a task under investigation, with the following algorithms being experimented: K-means, Lingo, STC (Suffix Tree Clustering). [Pragna Makwana, Prof. Neha Soni, Analysis and Comparison of Web Document Clustering Algorithms with Lingo, 2013]
So far LookinLabs makes no use of any kind of ontology. Our design choice was motivated by the principle of having no manual data to be entered in the service (ontologies are, in their classical forms, manually defined). However, the progresses made around Wikipedia have made some sorts of standard ontologies widely available. The most well-known instance is DBPedia, an ontology attached to Wikipedia. We can thus envision further cleaning our sets of keywords or topics by confronting them with such standard ontologies. Preliminary experiments have been undertaken. Final results are yet to come. An alternative approach would be to apply existing algorithms that build automatically some kind of ontology for a given data base of publications, e.g., by providing, for a given keyword, a set of neighboring keywords best correlated to it. An example of such an algorithm is Word2Vec. [https://en.wikipedia.org/wiki/Word2vec]
LookinLabs makes extensive use of Elasticsearch and is developed under Angular. These two tools are subject to updates, which impacts LookinLabs and thus requests a maintenance of the service to keep proper alignment.
Conclusions and perspectives
Our main conclusion is that bibliographical data bases (HAL for France, DBLP, IEEE Explore, Arxiv, etc) are probably not sufficient to deliver a service like LookinLabs with sufficient quality. The reason is the lack of homogeneity in the metadata (authors and affiliations). We are aware that search tools exist that chase homonyms regarding individuals, but their robustness is still not satisfactory. Futhermore, they do not apply to groups of researchers such as teams or labs. A major difficulty is thus the need to synchronize the bibliographical data bases with administrative data bases, whenever available. Such data bases are, by definition, not universal. In our use cases, only Inria was able to offer the needed information in the due form.
Our initial plans included the extension of LookinLabs to HAL in its whole. The use of HAL was made mandatory by the ANR (Agence Nationale de la Recherche) and the AERES (the body in charge of evaluating universities, institutes, and labs, nationwide). But no clear specification of the metadata to be entered by the authors exists. We actually doubt that such a clear specification can be performed and then enforced, given the wide variability of teams or labs in their size, scope, and life, throughout the French research community. Therefore, the extension to HAL in its whole remains a challenge. It could become doable if progresses are made in our data mining algorithms and/or techniques to deal with homonyms in individuals or the variability of the nature of teams or labs.
The last question is: how far is our experience with LookinLabs reproducible in other contexts? We could envision large companies (the LookinLabs design team has ties with Orange, Safran, and SAP and some preliminary discussions were held). One difficulty is the nature of document data bases where the technical or scientific information sits. For academic researchers, we could rely on publications. In large companies; however, a large part of such information is not found in well structured texts, but rather in slidewares with lots of graphical material, not amenable of data mining techniques as we used. Maybe major consultant companies (Arthur Andersen, Mercer, etc) could be relevant targets, as these companies produce a huge amount of reports for their customers, stored in highly structured and labeled data bases. In such cases, however, issues of strict security and confidentality would occur, which we did not encounter in our case.
__________________________________________________________________________________________________
Activity Report March 2017
Albert Benveniste, William Dedzoe, Jean Hany
Side activities since the deployment of the last release of LookinLabs, January 2016
The year 2016 has been a year of deep changes in the orientation of the CominWeb project. The following decisions were taken:
- Support for the development and maintenance of the CominLabs public web site was continued.
- No other general action was performed regarding the CominWeb collaborative platform, besides the needed support to allow for the maintenance and updates of the CominLabs public web site. The reason is that we observed a lack of interest of the CominLabs researchers in the collaborative platform features that CominWeb offers (see below the Activity Report 2015).
- We decided not to deploy the other services we experimented, see the 2015 report for a description: the Activity Monitor (the NSA of CominLabs) and the automatic generation of Scientific Activity report from biblio data base. Due to the limited amount of resources, we preferred to concentrate on the most promising service.
Refocus: LookinLabs4HAL
Our major decision in 2016 was to find a different target for LookinLabs than CominLabs itself. We had preliminary discussions with two companies: Orange and SAP (a representative of SAP is member of the International Advisory Committee of CominLabs). In parallel, since our data based contained in particular items from HAL, we started investigating HAL as a possible target. In particular, in June 2016, we had some meetings with the group at Inria developing services around HAL-Inria (AnHALytics) and we participated to a meeting of the nationwide community of Open Data for Science. As a result we decided to take HAL as our target for the next version of LookinLabs. This will be performed in two steps. In a first step, we concentrate on the subset of HAL-Inria, where the problems are simpler. The extension to all HAL will be a future work.
Objectives of LookinLabs4HAL
Now, the population addressed is that of all Inria researchers since 1994. This population is structured into teams (équipes-projets Inria, équipes Inria, and a few more categories), plus 8 different locations (Inria Centres). Administrative data bases allow to ensure that the population of researchers and teams is quite clean (very few duplicates or misses). This is in contrast with the whole HAL population, which encompasses all scientists in France in all disciplines.
This being said, the services offered by LookinLabs4HAL remain the same as for LookinLabs, namely:
- Search for the researchers/teams best matching a scientific topic (keywords or text)
- Navigation by similarity across the population of researchers/teams
- Automatic profiling of researchers/teams
- Explanations for the answers to the queries
The new feature is that, now, both researchers and teams can be queried. Furthermore, they can be searched in a nested way: researchers within a team. This allows searching for relevant teams given a topic, and then for relevant researchers in each relevant team. We had discussions with the head of Inria showing that this would be seen as a very valuable service for the institute.
New difficulties with reference to LookinLabs
- HAL-Inria contains 86,000 items, which is medium, not big size. But the dual search for both teams and researchers makes it much more difficult to properly adjust the algorithms. For comparison, HAL-all comprises above 1,200,000 items.
- The cleaning of the “author” field of HAL is a real difficulty. The information regarding affiliations is not clean at all in HAL in general. Affiliations appear to be highly heterogeneous, ranging from narrow teams to big labs. Because we restricted ourselves to HAL-Inria, we could benefit from correlations with administrative data bases (BASTRI for the teams and RAWEB, the activity report of Inria), for years posterior to 2006. This is the main reason why we address HAL-Inria in a first step. This difficulty is expected to become much more severe for HAL-all.
Roadmap
We plan to deploy LookinLabs4HAL, restricted to HAL-Inria, by end of spring 2017.
__________________________________________________________________________________________________
We show below the activity report of the CominWeb project and the information about the most recent release of the LookinLabs tool.
The second release of the LookinLabs tool was deployed in January 2016.
Objectives
The original target of LookinLabs was the community of CominLabs researchers. For this community, the following services are provided by LookinLabs:
- Search for the researchers best matching a scientific topic (keywords or text)
- Navigation by similarity across the population of researchers
- Automatic profiling of researchers
- Explanations for the answers to the queries
An essential characteristic of LookinLabs is that it is supposed to be “zero-effort” for the researchers. This means that no data is asked from them, besides providing a links for their personal entries to some standard publications data bases (HAL, DBLP, IEEE Explore…). Using this information, the publication records of each researcher can be automatically updated, and then mined for extracting the wanted information using big data techniques.
The addressed population of researchers has size approximately 350, which results in about 20,000 items in the biblio data base. This seems like a big number, but one should remember that we gather researchers from very different communities having divergent publication standards.
Difficulties and solutions
- Despite the information asked from the researchers was very limited (from 2 to 4 relevant biblio links) it took us almost five months and a number of repeated requests, to have 350 (out of a total population of approximately 500) researchers registered. This showed that this part of our process could not scale up. In turn, this method provided us with a well indexed population of researchers, with no duplicates.
- Our first idea was to use the 20,000 bibliographical items for getting title+abstract and to complete this information by querying Google with the title for getting a pdf of the full text publication (possibly a variant of it). In a second step, we would decompile this pdf to XML using the Grobid tool. The rules of Google, however, prevent massive automatic querying unless a special subscription is made. We thus decided to work only with the data directly available from the bibliographical data bases (title+abstract when the latter is available). This is the method currently used by LookinLabs.
Technical elements
Given the size and nature of the population of researchers, there was no particular difficulty in the construction of the bibliographical data base for use by the text mining tools. Still, duplicates existed in the bibliographical items (a same paper appearing in more than one form, due to minor modifications in the title). This, however, did not penalize the mining activity.
Main tools in the whole processing performed by LookinLabs are the following. First of all, we use Elasticsearch, an open source tool for text analytics. We use Elasticsearch for indexing the data base. This first set of keywords is further enhanced using natural language processing techniques, to detect important composed keywords (di-grams or tri-grams) that characterize topics more finely. This enhanced set of synthesized keywords is then used when correlating researchers with a queried topic and for the other services.
Lessons learned
In its deployed version, LookinLabs is considered working well. This can be seen as a small size validation of the concept. Despite it is deployed and available, LookinLabs is, as of today, not much used. This is why we decided to refocus LookinLabs to a different target, see above.
__________________________________________________________________________________________________
For reference, we reproduce below the activity report of the CominWeb project, dated 2015, where all our trials were reported.
CominWeb, a Platform for operating the CominLabs Excellence Center as a Social Network
William Dédzoé, Bertrand Le Marouille, Albert Benveniste
1. Context, motivations and requirements
“We” are CominLabs, an Excellence Center (Laboratoire d’Excellence – Labex – according to the Programme Investissements d’Avenir of the French Ministry of Research) with a 14M€ support over 9 years. CominLabs gathers ten labs covering a broad sector of ICT in Bretagne/Nantes area:
- Foton: optics
- IETR: IC systems
- Inria-Rennes: mathematics and computing
- Irisa: computer science and engineering
- Lab-STICC: IC systems
- Latim: biomedical imaging
- LINA: computer science and engineering
- LTSI: biomedical signal and image processing
- MSHB: socio-economy of ICT
- Telecom Bretagne: optics and networking
This set of labs comprises about 1000 research & teaching persons and a number of PhD students. CominLabs performs applied research in ICT & health sectors, with a scope ranging from optics, microwave and electronics, up to over-the-top distributed services and applications. Previous level of cooperation between these different labs was modest and restricted to subgroups of the labs having close scientific background.
CominLabs lives in a rich ICT industrial landscape collecting major companies of the sector (Orange, Technicolor, and more) as well as a rich body of SMEs (particularly in Brest, Nantes, and Rennes).
One of the main challenges for CominLabs is, therefore, to find and build new synergies. This has been achieved in part by establishing a funding program of cooperative projects, born from a seeding activity run by working groups. This seeding activity could be developed for the starting period but could not get sustained over the whole life of CominLabs (9 years). We therefore decided to consider relying on a Cooperative Platform and running CominLabs as a scientific social network.
Cooperative research faces today the challenge of increasing bureaucracy and “data deluge”: proposals, reports, and project building cause an explosion in contents replicates with only slight variations, a reshaping of contents to adjust specific needs, the compliance with sophisticated enterprise or administration processes, and all of this results in an increasing time spent by the engineer over email and internet. The wild use of email aliases in cooperative activities has turned the generated email to SPAM. We envision a management of cooperative research under the slogan of zero-spam/zero-proposal/zero-report/zero-deadline. “4-zero management” is made possible thanks to existing advances in Web technology, recent progresses in research in the area of Social Network technologies, and innovative views on the Web-scale management of unstructured and structured data. CominWeb is a platform that aims at enabling 4-zero management of cooperative research activities.
CominWeb is the name of this platform. What are its requirements ?
CominWeb shall serve as a “Competencies Warehouse”
Many of the projects of CominLabs have a strong trans-disciplinary nature. The search for competencies and knowledge is therefore a need. Exposing competencies for outside CominLabs is also a need.
CominWeb shall enable activity monitoring
One of the difficulties research networks such as CominLabs are facing is awareness, by the direction of these networks, of ongoing activities and progresses made. This is, of course, related to the duty of reporting discussed hereafter. But it is in itself needed for CominLabs’ head to do its job of creating and maintaining synergies. Of course, once this is made possible, monitoring will also be accessible to anyone having the proper rights granted. Access control systems can thus enable personalized monitoring. It may be even of interest to allow for wide monitoring of non-restricted access activities. For such a case, access control systems (e.g., based on passwords) may not be appropriate, as it would put too strong a burden on people in charge of managing access rights. Adaptive policies from the area of social networks may thus be considered.
CominWeb shall enable easier reporting
As any government funded program, CominLabs must report to its funding agency (Agence Nationale de la Recherche, ANR). This has been and is a costly duty for EU funded Networks of Excellence (NoE), leading to a number of requests, by the heads of such NoEs, to the participating people, for reporting activities. CominLabs bears similarities with such NoEs. It is therefore required that CominWeb facilitates the scientific aspect of reporting activities and reduces its cost. (Financial reporting is a separate matter, not considered in this project.)
CominWeb shall enable all the above at a low cost for cominLabs people
usually, exposing competencies is by having individuals characterizing themselves through a set of keywords, or maintaining their own Web page.[1]
Monitoring the activity of teams or projects is typically not done by funding programs – CominLabs can be seen as such a program. For NoEs it is done, in part, at the price of constraining participants to announce their workshops or meetings using some fixed support, to populate a particular platform (it can be a simple wiki, or a more sophisticated platform).
In general, to prepare their own activity report, labs or networks thereof transfer the burden to their teams or individuals. While this is acceptable for labs employing individuals, it is much less acceptable for extra superstructures such as NoEs or Labex, as CominLabs is.
Of course, all the above activities cannot go without the due information. Information can’t be invented. It can, however, be reused when it exists. A key requirement on CominWeb will thus be the following:
- Avoid asking people to populate specific information bases, for the only purpose of fulfilling the considered task;
- Replace this, instead, by a best exploitation of big data techniques over existing data.
How relevant would be the above requirements for cominWeb, beyond CominLabs ?
A natural question is: how representative is the CominLabs context? It is, of course, representative of networks of academic labs having a long life duration, so that data mining techniques make sense in building competencies warehouses.
How far is it representative of large companies with several business units or branches? The main difference is the practice, in academia, of producing lots of referred documents (journal articles, conference papers, etc.). This yields good opportunities for exploiting available data bases of documents. We believe, however, that large companies typically possess their own data bases of documents, collecting patents, scientific publications, and referred internal documents. These can be exploited in the same way we drawn before.
2. Initial objectives and targeted use cases
We illustrate the principles of CominLabs approach through a few representative use cases. In this section we describe the initial version for these use cases. Actual developments are presented and discussed subsequently.
2.1 Producing a draft activity report, automatically
We begin with the first use case: providing assistance for the production of an activity report, by producing a draft version for its scientific part, automatically.
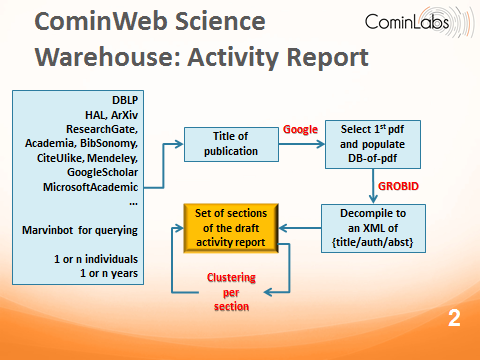
Figure 1: producing a draft activity report
Input : a database of publications
- We assume a list of individuals, e.g. the scientists members of CominLabs.
- For each individual, we assume the url of the entry (the entries) of the bibliography of this individual in some standard publication base of her/his community. For example, mathematicians use ArXiv, computer scientists use DBLP, France has requested his scientists to publish their papers in HAL. We have also listed a few search tools dedicated to bibliography. Some labs have their own data base.
Having this at hand, we use the top items of these data bases, consisting of {title+authors}, for each item. This is depicted as the second box in the figure.
Querying a search tool with title-or-paper or gathering XML of paper abstract, or paper body
Some databases give explicit access to the XML version of publication abstract (and, sometimes, publication body). Most databases, however, don’t. Direct access to such data requires having proper APIs from the involved publisher, something we do not consider doing. Instead, we query a search tool with title-of-publication (author names may be included in the query) and get as a first ranked pdf with high probability the pdf version of the publication or a preprint of it. Having done this we obtain a database of pdf documents, shown as the 3rd box in the figure.
Reverse engineering pdf to XML
Tools exist that reverse engineer pdf documents of scientific publications to an XML file. As an example of such tool, we have experimented using GROBID. To keep it reasonably efficient, we restrict the reverse engineering to return {title+authors+abstract}; this is shown in the 4th box of the figure. Alternatively, we assume XML text to be available by some mean.
Clustering the database of abstract into sections for an activity report
The draft activity report is obtained by clustering the above data base of abstracts into a limited number of sections. Clustering tools to achieve this should preferably offer the following features: 1) Proposing a title for the section, or, at least, a set of keywords; 2) Proceeding by incremental clustering with a statistical help to decide upon the best number of sections in a user specified range.
2.2 Searching for competencies

Figure 2: competencies warehouse
Figure 2 depicts our second use case. The objective is to answer queries such as “who does what on…”, an important need in large distributed research organizations or companies. The process begins with the same stages 1—4 as for the use case of Figure 1: producing a draft activity report. Then, it proceeds as follows.
Querying the database of XML abstracts for best correlated items with respect to the query content
The important point here is that, in order for the query to be precise and subtle enough, the classical query with keywords and matching is not good enough from the semantic point of view. The semantic web community has improved the relevance of keywords by using instead ontologies, which can be seen as domain specific complex structured keywords. Building ontologies, however, is a significant investment and suffers from the need for maintenance and revisions. We do not consider it to be appropriate for more open and flexible organizations such as CominLabs. The same consideration holds for distributed research organizations or companies. We are therefore seeking for keyword-free, ontology-free approaches to correlation.
Getting competencies and people
Calling the above search tool returns best correlated items in the document warehouse. The user can then process this information manually, possibly following cascaded correlation links. Alternatively, ranking can be applied to the resulting set of authors and returned to the user.
2.3 Activity and work-in-progress monitor
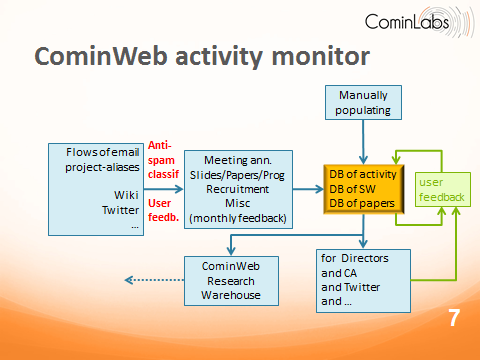
Figure 3: activity monitor
Figure 3 explains how the scientific activity of a distributed research community can be monitored.
Input : communication streams
It is assumed that the considered community is structured into groups, each group uses a group-alias for email, and email is the standard mode of communication. If email is the standard mode of communication, then the only burden put on the shoulders of individuals is to communicate by using agreed email aliases. Alternatives can be other streams of information, e.g., from wikis or social networks.
Classifying messages
Classification of messages is then performed by using techniques similar to anti-spammers (adaptive clustering with user’s feedback). Aim is to identify the following classes of messages: 1) Announcements of meetings or events; 2) Messages with attachments; 3) Other
From the first item, a dashboard of group activities can be built. Draft documents (papers and slides) can be collected from the second item. The resulting information is stored on a repository and can be corrected and updated by users at will – automatic collection of information is the default option, not the only one.
2.4. First experiments
In this section, we describe first experiments that were performed by using a prototype tool for correlation mining, developed by the Marvinbot SME.
A glimpse of Marvinbot tool
This tool, named mARC, is a big data technology for correlation mining. The tool processes streams of data. Any kind of data can be processed – so far we only tried documents. Correlations are constructed on the fly while documents are browsed. The tool works with no need for supervised learning, no need for any kind of ontology and no parameter for tuning, which makes the tool a priori highly attractive for our needs.
Since this technology is not mature and largely unexplored, CominLabs has launched, in cooperation with the Marvinbot company, a specification and benchmark study. The study is led by Vincent Claveau, a researcher at Inria working on natural language processing and information retrieval. Results of this study are in part inconclusive, as technical problems with the version we used in these experiments prevented us from having full confidence in our results. For the moment, we decided to develop our CominWeb services with more established technologies, while keeping this new tool as a candidate alternative subject to future reinspection. We report below shortly two experiments that we nevertheless did by using this tool. These experiments resulted in interesting lessons regarding how a user should interact with this kind of technology.
Two experiments using the mARC Marvinbot tool
The HAL-Inria document base has been used as the triple {title,author,abstract}. This data base was queried for best correlation with the abstract of another article, provided to us by the courtesy of an engineer from SAP. The submitted original abstract was the following:
The success of organizations or business networks depends on fast and well-founded decisions taken by the relevant people in their specific area of responsibility. To enable timely and well-founded decisions, it is often necessary to perform ad-hoc analyses in a collaborative manner involving domain experts, line-of-business managers, key suppliers or customers. Current Business Intelligence (BI) solutions fail to meet the challenges of ad-hoc and collaborative decision support, slowing down and hurting organizations. The main goal of our proposed architecture, which will be implemented in a future research project, is to realize a highly scalable and flexible platform for collaborative, ad- hoc BI over large, possibly distributed, data sets. This will be achieved by developing methodologies, concepts and an infrastructure to enable an information self-service for business users and collaborative decision making over high- volume data sources within and across organizations.
mARC returned as best correlated items a series of papers dealing with ad-hoc networks, in the general area of networking in telecommunications. This lead us identifying that some words in the submitted abstract were misleading; they are highlighted in red. We identified a few more trouble making words and decided to resubmit the following, slightly modified, abstract:
The success of business organizations depends on fast and well-founded decisions taken by the relevant people in their specific area of responsibility. To enable timely and well-founded decisions, it is often necessary to perform analyses in a collaborative manner involving line-of-business managers, key suppliers or customers. Current Business Intelligence solutions fail to meet the challenges of collaborative decision support, slowing down and hurting organizations. The main goal of our proposed architecture, which will be implemented in future research project, is to realize a highly scalable and flexible platform for collaborative Business Intelligence over large, possibly distributed, data sets. This will be achieved by developing methodologies, concepts and an infrastructure to enable an information service for business users and collaborative decision making over high volume data sources within and across organizations.
A video of this experiment is available at url http://people.rennes.inria.fr/Albert.Benveniste/pub/SAPPaperRecording.mp4
A video of a search for competencies is available at url http://people.rennes.inria.fr/Albert.Benveniste/pub/SearchCompetenciesKermarrec.mp4
The following preliminary conclusions were drawn:
- our databse HAL-Inria is a collection of 40,000 abstracts with a mix of English and French;
- According to the designers of mARC, this may be the reason for mARC getting confused by wrong keywords. Getting deeper concepts on which to base correlation would require a larger document base. This can be envisioned, either by having a larger warehouse, or by accessing the full articles, not only the abstracts. The latter approach is interesting when not so large document bases must be handled, such as for the CominLabs community. It, however, requires having a very efficient pdf2XML translator; our tool GROBID had hard times achieving this.
- Manual messaging of the queries will probably be needed anyway. After all, performing this is routine when querying with Google and it should not come as a surprise that massaging is needed in our case too.
3. Searching for competencies with LookinLabs
3.1 Service description (try it)
LookinLabs is the first advanced service of CominWeb. You can query LookinLabs in two ways.
- Searching for competencies in CominLabs is achieved by submitting, as a query, a description of the kind of competence you are looking for. Description can be either a list of keywords, the abstract or the introduction of an article, or simply any text describing the area of interest. The tool returns an ordered list of researchers and you can visit their publications and similar researchers of CominLabs.
- You can also search for publications relevant to a topic entered as a query. The description of the topic follows the same principles.
Here are two typical examples of queries that you can submit:
- Cloud computing big data (this is an example of querying using keywords.)
- The success of business organizations depends on fast and well-founded decisions taken by the relevant people in their specific area of responsibility. To enable timely and well-founded decisions, it is often necessary to perform analyses in a collaborative manner involving line-of-business managers, key suppliers or customers. Current Business Intelligence solutions fail to meet the challenges of collaborative decision support, slowing down and hurting organizations. The main goal of our proposed architecture, which will be implemented in future research project, is to realize a highly scalable and flexible platform for collaborative Business Intelligence over large, possibly distributed, data sets. This will be achieved by developing methodologies, concepts and an infrastructure to enable an information service for business users and collaborative decision making over high volume data sources within and across organizations. (this is a query consisting of the abstract of some article.)
3.2 The data
The only input data of LookinLabs are the Publication ID (PubID) of all researchers of CominLabs. As an example, for the third author of this note: Benveniste PubID consists of the triple:
http://haltools.inria.fr/Public/afficheRequetePubli.php?auteur_exp=Albert,%20Benveniste&CB_titre=oui&CB_article=oui&langue=Anglais&tri_exp=annee_publi&Fen=Aff for HAL bibliographical base
http://www.informatik.uni-trier.de/~ley/pers/hd/b/Benveniste:Albert for DBLP
How these PubID were collected is described subsequently.
Using the PubID we were able to construct a data base of documents, which we call the biblio base, where each document (a publication) consists of title, authors, abstract, and, whenever possible, an approximation of the body. How the biblio base is constructed is described subsequently. Some simple processing allows getting rid of part of the duplications or homonyms; duplications can be tolerated, however. The biblio base is our knowledge base for searching competencies. The biblio base is updated automatically, by polling the biblio urls periodically for new items.
3.3 The technologies
The LookinLabs engine must be any kind of document correlation tool, i.e., any tool able to return a clustering of a data base of documents. LookinLabs uses this engine to return the cluster of the biblio base containing the query. In addition, the clustering allows navigating in the population of returned items.
The first release of LookinLabs relies on the open tool elasticsearch. To cluster search results we rely on Carrot2 an open search results clustering engine. Carrot2 can automatically organize small collections of documents into thematic categories.
Keywords may, at times, be misleading. It would be thus interesting to use tools finding deeper, more semantic, correlations. This was our motivation in experimenting the Marvinbot technology, see Section2.4.
3.4 Status
- Database of PubID: it may not be complete as it proved to be more difficult than expected to get an up to date list of personnel of the constitutive labs of CominLabs. We are still working at completing this PubID base.
- The associated biblio base covers publications from the period 1965-now. Of course there is no guarantee that all those publications were written while their authors were with one participating lab of CominLabs. But this is an irrelevant defect, since we are interesting in identifying competencies, not providing an official publication list for h-indexing…
- So far the list of “best correlated people” returned is flat and simply ranked. To help the user to navigate in the responses of the service, it would be desirable to return the set of “best correlated people” in a clustered form. This way, the user could quickly discard some of clusters and focus on the clusters of interest to her. This improvement is planned for the second release.
3.5 Lessons and perspectives
It is worth sharing the lessons learned while developing LookinLabs. The major difficulties were not the ones we expected (we expected the correlation algorithms to be the crux).
A first difficulty was to collect the PubID. Strangely enough, lists of personnel of our labs were not always up to date. Worse, getting from the colleagues their PubID turned out to require much creativity, to meet our moto of “zero-effort services”. We spent some time writing an email to everyone, motivating people to respond to our request; this email provided a link to a web questionnaire (it would have been better to include the Web questionnaire as part of the email, but the email technology does not allow this, to the best of our knowledge). The web questionnaire asked for the email of the person, and then propose automatically synthesized PubIDs. Each PubID could be tested by the person for verifying its correctness, and otherwise corrected manually by the person. You can try yourself the questionnaire.
A second difficulty is to construct the biblio base, once the PubID are handy. Some standard bibliographical data bases follow the open data philosophy by providing explicit access to their data (title, authors, affiliations, abstract, but generally not the body); an instance of this is the HAL data base for France, covering all disciplines. Other standard bibliographical data bases would redirect the query to the publishers, who, quite often, forbid repeated queries by computer programs. Also, some of the texts of interest, e.g., abstracts of papers, were sometimes available, not in text format, but in pdf. A decompilation was therefore necessary, using a pdf2XML translator, which involves heavy processing. All of this resulted in a higher cost than expected, for constructing the initial biblio base. Updates require processing less items, however, and should not raise serious difficulties.
4. Two develoments in progress
In this section we report on the other two services of our work plan. None of them is fully deployed at the moment, for various reasons explained below.
4.1 Activity monitor
The activity monitor is, for sure, a routine technology at the NSA and similar agencies. Our service here is not operating behind the scene but openly, based on known rules and processes. Objectives of this service are twofold: 1) allowing heads of CominLabs to have an eye on what’s going on, and 2) to complement the biblio base with unpublished documents corresponding to ongoing research.
Service description
Team work produces logs of exchanges between team members, through email, wiki, or any kind of shareware. If we are able to get such logs and analyze their contents, we may be able to extract the following information of interest:
- Announcements of various kinds of meetings
- Draft in progress, either as attachments to email or as data sitting in sharewares
Using available technologies such as email classifiers, we could get the above.
The data
Input data for the service, as it was initially planned, consisted of group alias for email, where the group is any project or activity funded by CominLabs. We have thus asked each CominLabs project to create a project alias, include in each alias a CominWeb robot, and use this alias.
The technologies
We have developed a mockup involving a mail classification engine to classify mails into the following categories: mail with announcement of meetings, mail with attachment of interest, and other mail. A fake CominWeb mail actor returns to the users the result of its classification, for each mail. Means are given to the user for correcting this classification. This very much follows the process of anti-spam classifiers, albeit with a looser integration in the mailer.
Our implementation of the activity monitor service relies on Apache Mahout, a scalable open-source machine learning and data mining library.
Status
The prototype service was deployed in September, for experiments. So far we did not decide to deploy this service, despite its high usefulness.
Lessons and perspectives
The following problem prevented the Activity Monitor to perform as we hoped: the email aliases were not enough used. Today, the data base of collected emails has below 300 items. This is too low to perform any kind of classification. This may not be an issue by itself, as results of classification are returned to users for possible correction. Worse, however, we observed that very few attachments of interest were found. There may be two reasons for this disappointing fact.
First, our population of researchers may be too narrow. Since we rely on email aliases, we can only ask CominLabs funded activities to obey our request. This is a total of about 50 persons. Other colleagues from CominLabs territories (the 10 participating labs, with a total of about 500 researchers) cannot be monitored by using this technique. One could hope that the approach could work if the population is larger.
Another reason may be that part of the researchers would not exchange draft scientific documents while they are producing them, but rather use collaborative development tools with versioning services (Google Docs or svn are instances of such tools). We plan to investigate the feasibility of monitoring such sharewares. We are not very optimistic, however, as such tools are also used for IP related security reasons, so most researchers would probably be reluctant to open access in one way or another.
Now, it turns out that, in France at least, the widespread use of the HAL open access publication base has led many researchers to use it as a pre-publication to fix credentials. This way, the delay between ongoing competencies and what can be deduced from HAL contents get reduced.
4.2 Automatic Activity Report
Our initial plans as developed in Section 2.1 are still relevant, as we think. We are, however, faced with the issue of size of the document base. As we already said, the set of CominLabs funded activities involves about 50 researchers, which yields probably too small a document data base composed of all publications of the year, for submission to a clustering tool. The approach may still be valid, however, for a larger community. For this reason we have downgraded the priority of this task in our work plan.
Accordingly, the activity report of the CominLabs projects is still produced manually.
On the other hand, we have provided assistance for the production of the bibliography. Provided that relevant publications properly acknowledge CominLabs (no need for a formatted sentence, the only mention of CominLabs or an approximately written version of this term suffices), we have developed a tool that exploits the PubID of all participants of a given CominLabs project by automatically importing the bib of all papers acknowledging CominLabs. Users still have the possibility of writing their bibliography manually, but the means we have provided for this are uncomfortable on purpose, as an incentive for CominLabs researchers to properly acknowledge the lab.
5. Technical aspects : status and future plans
5.1 The current version (Jan 2015)
The CominWeb platform is built on top of Liferay, a framework for constructing Web portals, collaborative platforms, and social networks on a single platform. CominWeb hosts the CominLabs web site. The current version dated Jan 2015 has the following features.
CominWeb offers advanced search services (LookinLabs) relying on big data technologies, see Section 3 for details.
CominWeb offers an intranet with the following services, globally or for each CominLabs group, all services stemming directly from Liferay:
- A document warehouse
- A wiki
- A Readme, a FAQ, a forum
- Public pages for reporting activities
For this version, access is managed by using the classical techniques offered by Liferay, namely roles and assignment of rights to roles. People are manually registered together with their role. Registering CominLabs people was cumbersome. Updates and modifications would require a full time web master, something that we want to avoid.
5.2 Future plans for 2015 and beyond
Exploiting user feedback
Users of CominWeb will provide us with feedback. Users will consist of 1) the CominLabs members, 2) external people, 3) the International Advisory Committee (IAC, see the description of the governance of CominLabs) in charge of selecting the CominLabs projects and evaluating them, and, finally 4) the PIA/ANR evaluation committee, in charge of evaluating all Labex of France (first evaluation in June 2015).
A system of tags for the management of CominWeb
Our need is to be able to grant roles and qualify items in warehouses adaptively, depending on varying interests such as learned from social activities. The concepts and tools offered by Liferay are too low level for performing this. We therefore plan to develop a more flexible platform architecture by relying on a unique notion of tag. Tags are XML documents acting as meta-data for qualifying both users and items in warehouses. Tags will be translated into specific Liferay roles depending on the context and the same will hold for tags attached to documents or items. Tags can then be learned from social activities and vary adaptively.
Enhancing the LookinLabs service
The following enhancements are planned:
- Clustering of the names of researchers returned by the competency warehouse, see Section 3.4.
- Exploring the use of semantic based correlation engines.
- Exploiting user feedback.
- Introduction of the concept of “diversity” in search results
- Development and integration of scientific articles recommendation widget based on HAL RSS streams.
Exploring how the Activity Monitor could be developed
See Section 4.1.5 for details.
Automatic activity report
See Section 4.2 for details.