
Free Viewpoint Television (FTV) is an emerging application in which a multimedia content is transmitted to users such as they are enabled to choose and change the viewing angle in real time.
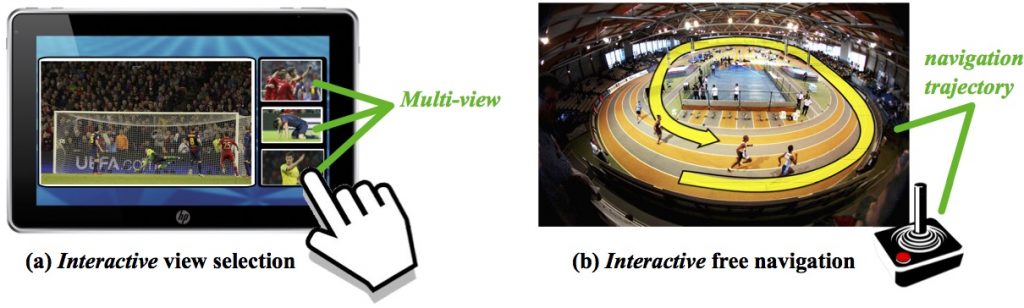
In other words, users have the possibility to observe the scene from the viewpoint they want: either by choosing between a predefined set of views (figure (a)), or by freely navigating in the scene (figure (b)).
The target applications are numerous: transmission of sportive and cultural events, but also for augmented reality applications for example in the “industry of the future 4.0”, education and health.
Many industries and research laboratories are nowadays working to develop such FTV systems. The current research issues deal with the following steps of the processing chain:
- Acquisition : The acquisition for FTV presents many problems because of their huge size. Indeed, in order to enable a high quality navigation, it is required that the user has access to a number of viewpoints sufficiently large to cover a complete wide 3D scene. This makes the acquisition very costly. Moreover, the calibration algorithms used for small captured systems have to be revisited since FTV brings huge distance.
- Representation : Once data is captured, the “representation” step consists in re-organise the description of the signal in order to better adapt the transmission constraints.
- Compression : Contrary to “traditional” compression in which all the data is sent to the user, the specificity of FTV is that the transmission system has to transmit only what is required by the user. Indeed, this is not necessary to transmit all the scene when the user is only looking at one specific subpart of it. However, since online encoding is not conceivable, the main problem is to design a compression strategy that encodes all the data a priori such that only a subset could be extracted after the user request.
- Interaction/Transmission : Organizing the user interaction, the bitstream extraction and the transmission of the information over the network are the main issues related to that step. This is moreover a problem when the number of users is high.
- Decoding and Rendering : The purpose is to ensure a high quality navigation for the user, based on virtual view synthesis algorithms while keeping the complexity low in order to produce FTV for every device.
Nowadays, research are made all over the processing chain. However, one can observe a significant lack of suitable video sequences for testing the algorithms. Indeed, most of the developed works are validated on “small” datasets (low number of camera and small indoor scene).
In order to develop a good FTV systems, a sequence must follow the following constraints:
- a high number of view must be accessible (>100 as required by MPEG)
- a complex navigation possibility (not only linear)
- an heterogeneous action with attractive and less interesting regions (e.g., a soccer game)
- a sufficiently long length (at least 1 minute) in order to simulate user navigation
- calibration parameters (internal and internal parameters)
- depth maps
The datasets shared on this website are based on omnidirectional cameras to provide new multi-view sequences, suited to FTV. To know more how we did our capture click here.