
Final Report
You can download the final report for NOP here.
Challenge 1: Develop sound formal foundations for intermittent systems
To address this first challenge, we have proposed a new energy-aware model of computation for intermittent systems. In this model, computations are expressed as a set of activities, where an activity is associated with a mode of operation of the hardware platform. A mode is a configuration of a subset of hardware resources such that the physical characteristics that determine energy consumption as a function of time are constant. In other words, the energy consumption generated by the execution of an activity is only a function of the duration of the activity. Activities are designed so that they can be performed in a single load cycle: an activity that is too long has therefore to be split into several parts. When executed correctly, an activity finishes in the same cycle in which it was started. There is therefore no need to save its context, or to take special precautions to generate idempotent code (which is necessary when the code can be replayed). Activities can be linked by precedence constraints (one waits for a result produced by another), exclusion constraints (they share physical resources), etc. Finally, each complete execution of an activity brings a reward to the system.
To model systems based on this model of computation, we have proposed a new class of cost-based time Petri nets. Petri nets naturally express communication, parallelism, sequencing, and resource sharing. Time addition is used to model the duration of activities, as well as periodic events and deadlines. Finally, two functions are used: 1) a discrete function to model the reward accumulated during a computation cycle, and 2) a linear function to model the energy consumption resulting from the execution of activities.
This allows us to unambiguously express the set of possible behaviors of an intermittent system by capturing its different dimensions: its control flow, its data flow, and its resource consumption in the time and energy domains. This work is described in [2].
Challenge 2: Develop precise predictive energy models of a whole node usable for online decision making.
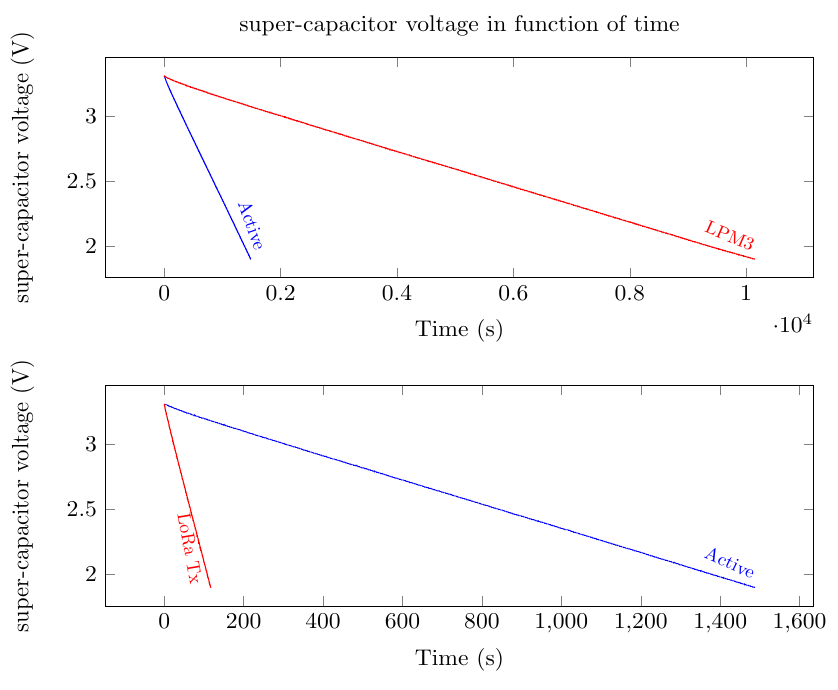 Experimentally, we have validated the fact that the consumption of the platform in a given mode, over a ‘short’ duration (i.e., typically corresponding to the execution of an activity), can be approximated sufficiently accurately by a linear function of a measurable physical quantity. Examples of such functions are given on the figure on the right of the text. Two cases can then be distinguished. If the energy buffer is directly connected to the energy harvesting system, the physical parameter is the voltage across the energy buffer. If a voltage regulator is placed between the energy buffer and the energy harvesting system, the physical quantity is the square of the voltage at the terminals of the energy buffer. This model is used to characterize the energy consumption associated with each mode of the platform and thus indirectly the activities of the system.
Experimentally, we have validated the fact that the consumption of the platform in a given mode, over a ‘short’ duration (i.e., typically corresponding to the execution of an activity), can be approximated sufficiently accurately by a linear function of a measurable physical quantity. Examples of such functions are given on the figure on the right of the text. Two cases can then be distinguished. If the energy buffer is directly connected to the energy harvesting system, the physical parameter is the voltage across the energy buffer. If a voltage regulator is placed between the energy buffer and the energy harvesting system, the physical quantity is the square of the voltage at the terminals of the energy buffer. This model is used to characterize the energy consumption associated with each mode of the platform and thus indirectly the activities of the system.
We did also investigate the energy consumption at the instruction level, taking into account the impact of the micro-architecture. The platforms we are targeting are very simple in terms of micro-architecture (2 pipeline stages, no speculative mechanism, instruction cache only, etc.), so a simple model quickly seemed sufficient. A distinction is made between instructions that access data memory and other instructions. For the former, a distinction must be made between accesses to volatile memory (typically SRAM technology) and non-volatile memory (typically FRAM technology). For the latter, a distinction must be made between simple instructions that are executed in one cycle and more complex instructions that require several cycles. This information can be found in the documentation of the platform.
With regard to taking into account the energy harvested: most of the work in the literature focuses on a fairly large time granularity, of the order of an hour. This grain may be relevant for planning the execution of the whole application on a daily scale, but this problem is not currently addressed in NOP. We are more interested in the scheduling of activities, which implies a time grain one or two orders of magnitude smaller. Existing models are not adapted to this grain; moreover, when confronted with the databases available online, the models in the literature that we have implemented have a high error rate, of the order of 30%.
Recently, as part of the internship of S. Srinath, we studied models for predicting the time required to enter idle mode in order to re-fill the energy buffer to a given level. We assume that the power supplied by the harvesting device is constant over the period of time corresponding to the refill of the buffer. According to our initial experiments on the target, this assumption appears to be valid for time intervals up to a few minutes. The first results are promising, but work remains to be done to optimize the trade-off between accuracy and model complexity.
 Finally, we introduced WORTEX, a comprehensive ecosystem designed to create WCEC/WCET models at the granularity of the basic block, tailored to a specific architecture. To ensure the real-world applicability of its models, WORTEX extracts large basic block datasets from real programs sources and precisely measures their energy consumption/execution time on the physical target platform. This dataset serves as a foundation to train various WCEC/WCET models using diverse machine learning techniques. While these techniques produce reliable and accurate WCEC/WCET models, they can sometimes appear cryptic, leading to concerns about their trustworthiness. To address this issue, WORTEX adds explainability to those models, enhancing their reliability and transparency. We seamlessly integrated WORTEX into a conventional WCET IPET tool, allowing the analysis of entire programs and evaluated WORTEX predictions at both the program scale and basic block scale. Results show that WORTEX provides conservative estimate with reasonable accuracy, with around 32% overestimation on average. Submission of a publication related to WORTEX is expected soon.
Finally, we introduced WORTEX, a comprehensive ecosystem designed to create WCEC/WCET models at the granularity of the basic block, tailored to a specific architecture. To ensure the real-world applicability of its models, WORTEX extracts large basic block datasets from real programs sources and precisely measures their energy consumption/execution time on the physical target platform. This dataset serves as a foundation to train various WCEC/WCET models using diverse machine learning techniques. While these techniques produce reliable and accurate WCEC/WCET models, they can sometimes appear cryptic, leading to concerns about their trustworthiness. To address this issue, WORTEX adds explainability to those models, enhancing their reliability and transparency. We seamlessly integrated WORTEX into a conventional WCET IPET tool, allowing the analysis of entire programs and evaluated WORTEX predictions at both the program scale and basic block scale. Results show that WORTEX provides conservative estimate with reasonable accuracy, with around 32% overestimation on average. Submission of a publication related to WORTEX is expected soon.
Challenge 3: Significantly improve the energy efficiency of run-time support for intermittency.
From this point of view, we have developed two contributions. These two techniques are inspired, at least in part, by work developed in the ‘real-time’ community, which seeks to integrate a physical dimension (time) into software technologies.
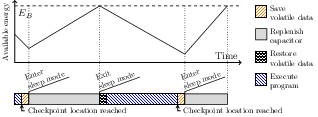 The first contribution is a technique for optimizing the code generated during the compilation of an intermittent program. This technique, which we have named SCHEMATIC, aims to co-optimize the placement of variables in memory and the positioning of checkpoints, subject to energy and memory size constraints. It is useful for cutting out activities that are too long to be executed in one cycle. The checkpoints positioned in this way naturally mark the boundary between two activities. Checkpoint placement is a central problem in intermittent computing. If there are too many checkpoints, there will be a significant increase in the cost of checkpoint management; if there are too few, there will be a significant increase in the cost of replay of uncommitted code. The ideal situation is illustrated on the Figure on the right of the text, when exactly one checkpoint is taken just before the end of the current activity cycle. When it comes to placing variables in memory, there is a choice between volatile and non-volatile memory. Volatile memory offers fast access and low power consumption, but requires the variable to be copied to/from non-volatile memory at checkpoints. The second avoids these copies at the cost of slower, more power-hungry access. The optimal choice for a given variable therefore depends on the number of accesses between two checkpoints. Unlike work in the literature that focuses on one problem (either memory placement or checkpoint positioning), we have developed a technique that allows us to tackle both problems together. It is a greedy technique, based on partial exploration of all paths in the control flow graph until all arcs are covered. On a series of benchmarks from the literature, the energy required to execute code generated by SCHEMATIC always compares favorably with that of state-of-the-art techniques, with reductions of up to 51%. The work on SCHEMATIC will be presented at the CGO 2024 conference [1].
The first contribution is a technique for optimizing the code generated during the compilation of an intermittent program. This technique, which we have named SCHEMATIC, aims to co-optimize the placement of variables in memory and the positioning of checkpoints, subject to energy and memory size constraints. It is useful for cutting out activities that are too long to be executed in one cycle. The checkpoints positioned in this way naturally mark the boundary between two activities. Checkpoint placement is a central problem in intermittent computing. If there are too many checkpoints, there will be a significant increase in the cost of checkpoint management; if there are too few, there will be a significant increase in the cost of replay of uncommitted code. The ideal situation is illustrated on the Figure on the right of the text, when exactly one checkpoint is taken just before the end of the current activity cycle. When it comes to placing variables in memory, there is a choice between volatile and non-volatile memory. Volatile memory offers fast access and low power consumption, but requires the variable to be copied to/from non-volatile memory at checkpoints. The second avoids these copies at the cost of slower, more power-hungry access. The optimal choice for a given variable therefore depends on the number of accesses between two checkpoints. Unlike work in the literature that focuses on one problem (either memory placement or checkpoint positioning), we have developed a technique that allows us to tackle both problems together. It is a greedy technique, based on partial exploration of all paths in the control flow graph until all arcs are covered. On a series of benchmarks from the literature, the energy required to execute code generated by SCHEMATIC always compares favorably with that of state-of-the-art techniques, with reductions of up to 51%. The work on SCHEMATIC will be presented at the CGO 2024 conference [1].
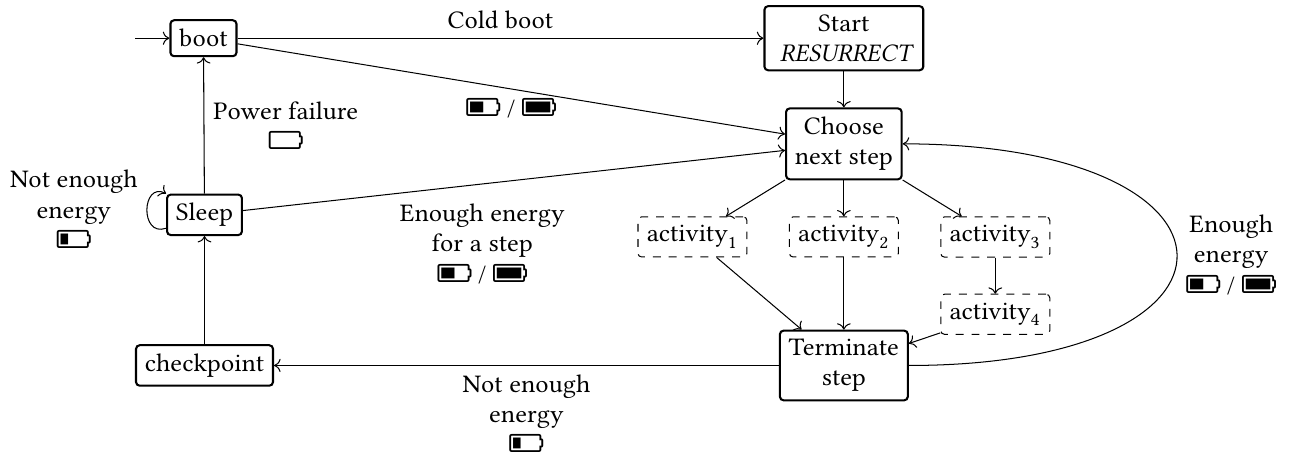
The second contribution is an energy-aware runtime that implements the above computational model. This runtime, which we have named RESURRECT, is based on the Trampoline RTOS. To minimize overhead, RESURRECT uses information that is computed off-line by static analysis of a cost time Petri net model of the system. This information is in the form of a directed graph where each arc is associated with a sequence of activities (possibly including parallelism) called a computation step. Nodes are associated with states of the system. An arc between two nodes indicates that the execution of the execution step transforms the state of the system from the initial state to the target state. From a node, several outgoing arcs can be followed. These arcs correspond to different condition concerning the level of available energy in the buffer, or the number of pending external events. The way in which this graph is obtained is explained below. During execution, RESURRECT follows this graph. After executing a step, the load level is measured. If this level is sufficient for at least one outgoing arc, execution continues. If not, the system enters ultra-low power mode until the load level is sufficient. This behavior is illustrated by the Figure on the right. This power-aware approach reduces the number of checkpoints made during execution. What’s more, there is no code replay. Finally, energy-intensive activities have a chance to be executed even when the energy harvest is low. On a number of benchmarks of the literature, RESURRECT compares very favorably with other execution support targeting reactive and intermittent applications. A paper on RESURRECT has been written and is currently under review.
Challenge 4 : Develop techniques to provide formal guarantee through static analysis of the systems behavior.
One of the specific features of the work developed in NOP is the adoption of an approach based on a worst-case analysis of resource usage, in order to guarantee execution without code replay and with a low number of checkpoints. To achieve this, it is necessary to ensure that resource consumption is predictable at runtime.
To guarantee the safety of the code generation technique, it is necessary to characterize the worst-case consumption of a path in a safe and, if possible, accurate way. To do this, we use the techniques developed for worst-case execution time analysis, re-targeted to address worst-case energy consumption. As mentioned above, the target hardware architectures are simple and can be analyzed using well-known techniques, including simple models, or derived from techniques such as WORTEX (cf. Challenge 2).
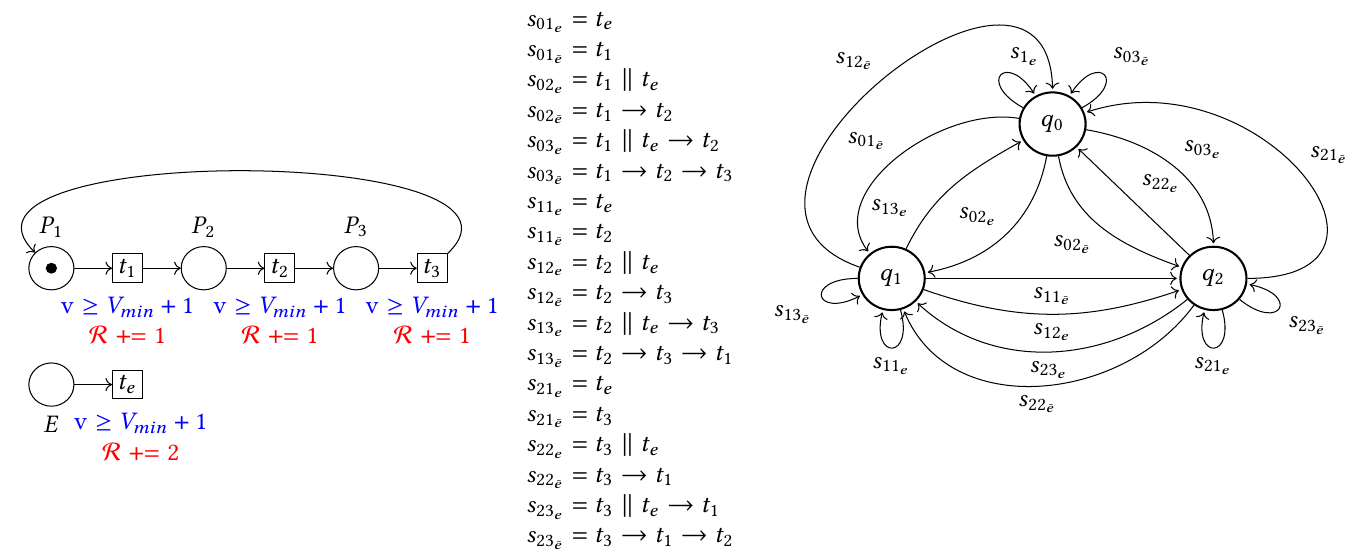
The limitation of this first technique is that it focuses on CPU and memory consumption. The consumption induced by the other hardware resources is taken into account in a second level of analysis, which exploits the formal models constructed by using cost time Petri nets. From these models, we compute a safe and optimized graph of execution steps, which can be played at runtime by RESURRECT. We have proposed a technique to compute the optimal set of executable activities in a given state. This involves exploring the symbolic state space of the model to identify the states that can be reached with a given initial energy level (and assuming zero incoming energy), then the state that accumulates the highest reward, and finally the least energy-intensive path to reach that state. Since this analysis quickly suffers from the problem of state space explosion, which is only partially contained by symbolic methods, we have also developed an approximate greedy technique, and an exact technique that does not require exhaustive exploration under certain conditions. This work is described in detail in [2].
Challenge 5: Develop a proof of concept: an intermittent system for song bird recognition, to assess the costs and benefits of the proposed solutions.
It is important to be able to validate the capability to perform intermittent tasks in a context where processing power may be limited, and the computational load is heavy. In the scope of the project, we aim to carry out a task involving the classification of bird soundscape. This task entails multiple steps that may or may not support intermittence: the capturing of sound signals with sufficient temporal and frequency resolution to discriminate between different bird species, the preprocessing of this data to extract fundamental features, the actual classification process, and the transmission of the aggregated classification data.
In the NOP project,  we are interested in a neural network-based classification approach due to its good detection performance. One of the challenges is that operational complexity and memory footprint are substantial, necessitating consideration of intermittence in the target system. The first project contribution was to create a small neural network suitable for classification, with a parameter count adapted to the available memory in the MSP430. This network was trained on a literature database. The second contribution involved implementing this network on the MSP430. An analysis of the trade-off between input data size and detection capability was conducted, as well as an assessment of the impact of the computation format, with all processing performed in fixed-point arithmetic. This work has been successfully carried out on an MSP430 evaluation board and will soon be implemented on an integrated board.
we are interested in a neural network-based classification approach due to its good detection performance. One of the challenges is that operational complexity and memory footprint are substantial, necessitating consideration of intermittence in the target system. The first project contribution was to create a small neural network suitable for classification, with a parameter count adapted to the available memory in the MSP430. This network was trained on a literature database. The second contribution involved implementing this network on the MSP430. An analysis of the trade-off between input data size and detection capability was conducted, as well as an assessment of the impact of the computation format, with all processing performed in fixed-point arithmetic. This work has been successfully carried out on an MSP430 evaluation board and will soon be implemented on an integrated board.