
Final report is available here
The Profile cominlabs project has been running for 3 years. It is a truly interdisciplinary where computer scientists, lawyers and sociologists interact to address the problem of online profiling. This project has produced various main contributions which are currently synthesized in a book entitled “Online profiling: between liberalism and regulation” (written in french). This book will be published in November and accompanied by a conference which will be held on Friday 27th of september 2019 in Rennes. This conference will synthesized the works made by the project and confront our ideas with other internationally recognized researcher working on the domain of private data and profiling.
One of the main result of the Profile project comes from the PhD Thesis of Pierre Laperdrix (his PhD was not funded by the project but he worked closely with us) which won the 2018 INRIA/CNIL price “Privacy protection” for his article “Beauty and the Beast: Diverting modern web browsers to build unique browser fingerprints” and the accesit to the Gilles Kahn 2018 Phd thesis price for his thesis “Browser Fingerprinting Exploring Device Diversity to Augment Authentication and Build Client-Side countermeasures”
CONTEXT
The profile cominlabs project has been studying online profiling for the last three years. The project is truly interdisciplinary with software computer scientists, lawyers and sociologists. We have been studying the envision impact and technical abilities of online profiling together with the tools to protect against this type of profiling both from a socio-technical and law point of view.
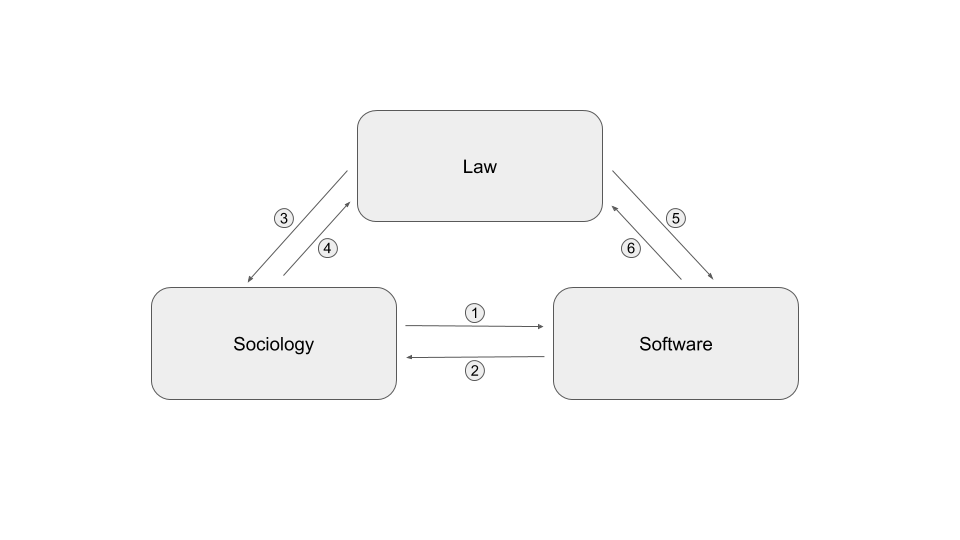
To carry out this research, the project includes three disciplinary fields that interacted together as shown in the diagram below. Each arrow corresponds to a type of exchange between two disciplinary fields. The nature of these exchanges is considered as a lesson learned from this project and is detailed below:
- Sociologists have interacted with computer scientists by studying the reactions of the general public to the phenomenon of online profiling and by highlighting the privacy paradox.
- The computer scientists interacted with the sociologists to define the specifications and co-develop a system to study the traces left by the use of a smartphone.
- Jurists have interacted with sociologists on the conditions for possible free and informed consent to profiling
- In-house lawyers interacted with computer scientists to identify and qualify the data involved in profiling.
- Sociologists and jurists worked on framework for the CGU of a future application aimed to collect data from users’ smartphones.
- Sociologists have presented their results to explicit the concept of “resigned” consent to jurists
CONTRIBUTIONS
Our contributions are organized into two themes :
- The privacy and profiling paradox: which state that most people really care about their privacy, but on the other hand they agree to give all their private data to access various services.
- Profiling regulation: the computer and legal control instruments enabling users to understand what the operator does with their data.
THEME 1 : THE PRIVACY AND PROFILING PARADOX
1ST CONTRIBUTION : RISKS PERCEPTION ANALYSIS FROM A SOCIOLOGUE POINT OF VIEW.
Relationships between users and smartphone collected-datas are our main focus point in this study. In that way, we developed a methodology based on users dataselves auto-confrontation.
While studies explaining those relationships can be analyzed through what is called Privacy Paradox (which balanced the users’ willingness to be protected against data gathering, and their practices generating collected data), we suggest that framing the question in this way is problematic because users are far from being enlightened as to what they have agreed to. When they noticed the variety and the quantity of collected-datas on them and their practices, the reactions we observed show most of the time: surprise and fears.
Observation and lessons learned : We noted that most consent were resigned consent and most users were trying to implement a protection scheme against data profiling but they had the impression they lack the tools and knowledge to be efficiently protected. These observation justify the need and drive the development of tools to protect user privacy.
2ND CONTRIBUTION “RISK ASSESSMENT OF RECIDIVISM. AN OCCURRENCE OF CRIMINAL PROFILING”.
What are the occurrences of criminal profiling? Rather than an overview, the choice was made to analyse an emblematic case of profiling and the evolution of criminal law at the same time: the assessment of the risk of recidivism. Increasingly, the old fear of new crimes being committed by offenders is leading contemporary legislators to reorient the functions of sentencing and criminal procedure. From the punishment of the past offence, the system shifts, at least in part, towards managing the risk of a future offence. Carried out at low noise, against the background of the challenges of this paradigmatic break in terms of fundamental freedoms, this evolution is promoted by new technologies, especially the application of algorithms for the purpose of profiling individuals. However, to date, it has not attracted much interest from legal researchers, especially in France.
Observation and lessons learned : In addition to a contribution relating to profiling in an interdisciplinary context, this study contribute to the development of the analysis of this neglected legal-political phenomenon.
THEME 2 : PROFILING REGULATION
1ST CONTRIBUTION : THE DGPR’S LEGAL SAFEGUARDS AGAINST DISCRIMINATORY PROFILING PRACTICES
Profiling is an essential concept aimed by the data protection regulation. In many country, it was because of the profiling that a data protection law was adopted. Naturally, the GDPR deal with this notion. Article 4 § 4 of the European regulation define it, and article 22 prohibit the use of profiling. However, the prohibition is not as clear as it seems and the goal of this contribution is to show why. First of all, article 22 prohibit every automated individual decision-making, not only profiling. Yet, the text of this article doesn’t implement a general prohibition of these techniques. It implement a right for the person. That is to say that “the data subject shall have not right not to be subject to a decision solely based on an automated processing”. Many information can be extract from this wording. On one hand, the data subject have, indeed, a concrete right to oppose to an automated processing. But, on the other hand, the sentence contain, in itself, the exception to the rule. If a human being can act on the processing, or on the decision, it means that the processing is not solely based on an automated decision. So the processing, is lawful. The other main right related to the profiling is the right to object to the processing. Once again, this right is not absolute because many exception are practical. An other exception to the profiling is the consent of the data subject. The consent, perceive as a protective right for the data subject, can mainly be a breach in data protection regulation. Many protective principle of the GDPR, like the prohibition of processing sensitive data, can be sidelined by the consent of the data subject.
Observation and lessons learned : All of these exceptions to the prohibition of profiling, and every concept approach in this contribution reveal the complexity of the profiling regulation.
2ND CONTRIBUTION : FRAMING PROFILING IN THE GENERAL DATA PROTECTION REGULATION (GDPR) IN THE LIGHT OF EUROPEAN INSTRUMENTS FOR THE PROTECTION OF FUNDAMENTAL RIGHTS
This contribution analyses the framework of profiling carried out by the General Data Protection Regulation (GDPR) of 2016 in the light of European instruments for the protection of fundamental rights, namely, on the European Union (EU) side, the EU Charter of Fundamental Rights 2000 and the Council of Europe, the European Convention on Human Rights (ECHR) of 1950 and the Convention for the Protection of Persons in Respect of Automated Processing of Personal Data of 1981. It should be noted that the latter Convention, known as Convention 108, will be examined in parallel with its modernized version, the so-called “108 + Convention”, even though the latter is not yet in force.
This contribution assesses the degree of alignment of the GDPR profiling framework with the European body of fundamental rights protection. The examination shall be based on the content of the relevant GDPR pivot article, namely Article 22 entitled “Automated individual decision, including profiling”, even if, on the one hand, this article does not concern only the profiling hypothesis and, on the other hand, not all profiling hypotheses are limited to the content of this article. If Article 22 specifies in its § 1 that the person concerned has the right not to be the subject of a decision based exclusively on automated processing, including profiling, producing legal effects on it or significantly affecting it in a similar way”, it then provides for exceptions to this right whose conformity with fundamental rights must be assessed (first part of the contribution) and it accompanies them with a number of guarantees whose articulation with fundamental rights must be examined (second part of the contribution).
Observation and lessons learned : Thanks to the convergence of the GDPR and the European instruments for the protection of fundamental rights, Internet users benefit from protection against profiling by web giants.
3RD CONTRIBUTION : INSTRUMENTS FOR REGULATING CONNECTED OBJECTS IN HEALTH INSURANCE
This contribution has two components. On the one hand, we have carried out a legal inventory of the situation on connected object links and health insurance and, on the other hand, we have considered what possible profiling practices based, in particular, on the data produced by connected objects may change in the field of health insurance. This raises the question of the legal regulations to be built for the protection of the insured person and the ethical use of data.
Observation and lessons learned : If the proposed law tabled on 23 January 2019, aimed at prohibiting the use of personal data collected by connected objects in the insurance field, does not result, the processing of personal data could become an instrument of differentiation in the market of health and/or provident insurance.
4TH CONTRIBUTION : MITIGATING BROWSER FINGERPRINTING
Browser fingerprinting is a technique that collects information about the browser configuration and the environment in which it is running. This information is so diverse that it can partially or totally identify users online. Over time, several countermeasures have emerged to mitigate tracking through browser fingerprinting. However, these measures do not offer full coverage in terms of privacy protection, as some of them may introduce inconsistencies or unusual behaviors, making these users stand out from the rest.
Observation and lessons learned : We address these limitations by proposing a novel approach that minimizes both the identifiability of users and the required changes to browser configuration. To this end, we exploit clustering protocols to identify the devices that are prone to share the same or similar fingerprints and to provide them with a new non-unique fingerprint. We then use this fingerprint to automatically “reconfigure” the devices by running a browser within a docker container. Thus all the devices in the same cluster will end up running a dockerized browser with the same indistinguishable and consistent fingerprint.
5TH CONTRIBUTION : OPEN THE BLACK BOX OF CUSTOMIZATION ALGORITHMS
The ever-increasing amount of personal data collected by profiling systems, online or not, is fueling the real-life implementation of highly personalized online services based on recent successful machine learning techniques such as deep neural networks. In a nutshell, these techniques input a detailed personal profile (ex : browsing history, or socio-demographic information with possible criminal background) and typically output a prediction (ex : a list of suggested products, or a score that quantifies the risk of recidivism). Despite the fact that these systems are used widely and intensively, their inner working is often opaque, both about the exact information they use and about the operations performed. Given that these systems may suffer from various biases (sometimes involuntarily) while they may impact strongly some individuals (ex : the result of judgment) it is crucial to be able to put them under scrutiny.
Observation and lessons learned : We advocate for a two-step approach that consists (1) in gathering pairs of (input, output) to/from these systems (ex : by constructing profiles and observing the resulting suggestions or prices) in order to (2) construct a human-understandable view of the way the system under study maps the inputs to the outputs. To the best of our knowledge, the existing methodologies for collecting data from these systems disclose information in an uncontrolled manner which may lead to a biased output for a given input. Proposing a robust methodology that limits the side leaks is thus our objective with respect to the first step. We have designed the methodology and are currently implementing it. The second step is related to explaining machine learning algorithms. Related works are numerous. As a preliminary study we have built a decision tree over the COMPAS dataset that contains profiles of criminals together with various predicted risks (ex : violent recidivism).