
In the previous sections, we developed features extraction methods and applied classification algorithms to identify five sedentary and ambulatory activity types from acceleration data. The developed methods proved their accuracy in detecting the activities in a controlled scenario. However, how these algorithms will perform in free-living scenario is undetermined. It is important to evaluate the reliability of these algorithms in naturalistic conditions and to adapt the classification models to such conditions.
Shifting from ‘Basic’ to ‘Pragmatic’ Protocols…
Initially, our work was established using a dataset collected in a controlled protocol. This ‘basic’ protocol encompasses a limited number and types of activities performed by 8 subjects for a predefined duration under the supervision of a researcher. Because it is important to ensure a naturalistic data collection protocol, we believe that this first dataset is not sufficient for a complete validation of the recognition system. For this reason, we carried out a new expanded protocol that could offer important insight on the system response in challenging circumstances.
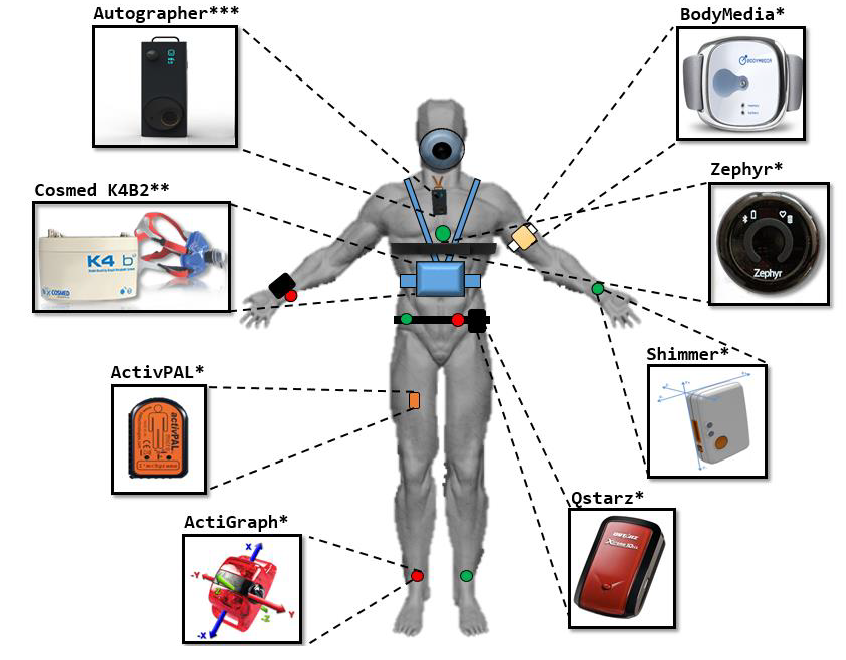
Figure 1. An illustration of the equipment and their positions on the body.
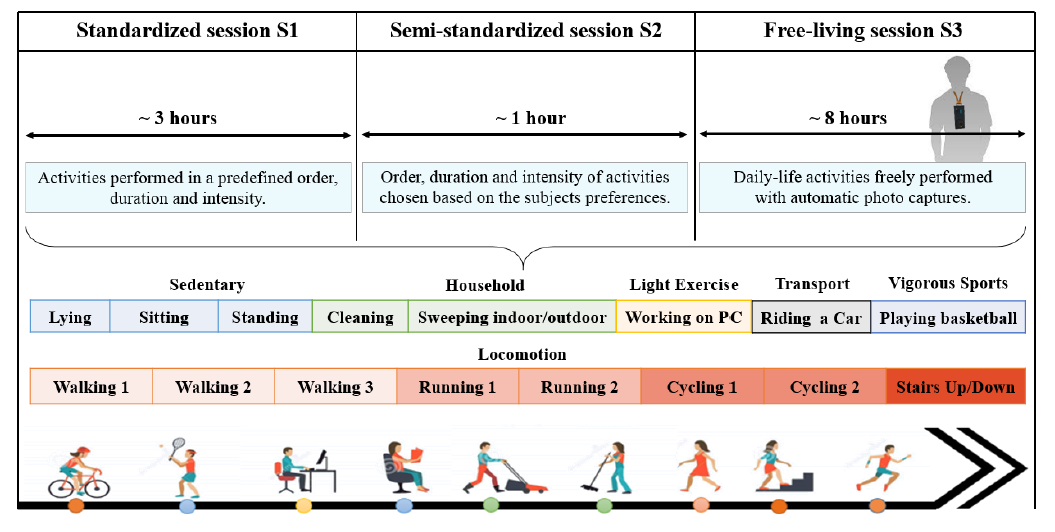
Figure 2. Description of the triple-session pragmatic protocol for data collection.

Figure 3. Examples of the performed activities.
Some Results..
Our intention here is to compare the recognition performance among the sessions.
The methodology that the majority of PA-controlled approach follow is : training the recognition model on a set of controlled data and then testing the model on a set of controlled data as well. We reproduced this procedure and did the same by training the model on our controlled data (from session S1), but we were interested in testing the developed model on a set of real-life session S3. Our hypothesis is that a trained model on controlled data will reveal a high performance when tested on controlled data but will fail at recognizing activities performed in uncontrolled manner.
 The comparison of the overall F-score values of the accelerometer sensors on the S1 test-set revealed high rates of classification for all three devices. However, by testing their accuracies on test-sets from Session S3, a dramatic drop occurred in the performance of all the three. Our hypothesis was thus confirmed by these results where a drop of around 40% is noticed from all the tested devices when applied on naturalistic test-sets.
The comparison of the overall F-score values of the accelerometer sensors on the S1 test-set revealed high rates of classification for all three devices. However, by testing their accuracies on test-sets from Session S3, a dramatic drop occurred in the performance of all the three. Our hypothesis was thus confirmed by these results where a drop of around 40% is noticed from all the tested devices when applied on naturalistic test-sets.
