
Tsunamis. Feux de forêts. Pandémies. Dans les situations d’urgence, des décisions clés peuvent être prises en exploitant très vite le déluge de données livré par des capteurs et autres appareils répartis sur de vastes zones. Mais si la production de données a explosé dans les dernières années, les capacités d’analyse rapide, elles, n’ont pas suivi. Des problèmes de latence ralentissent le transport des informations vers les lointaines fermes à serveurs du cloud computing. Une alternative commence cependant à poindre. On l’appelle ‘continuum computing’. Elle vise à exploiter les multiples ressources de calcul disponibles en amont, tout au long du réseau, pour analyser la donnée aussi tôt que possible et au plus près de l’endroit où elle est collectée. Le chercheur Inria Daniel Balouek étudie les nouvelles abstractions nécessaires à la fois pour fédérer ces ressources hétérogènes et aider les développeurs à construire des applications par-dessus.

Depuis 20 ans, le cloud computing constitue la clé de voute derrière la plupart de nos clics quotidiens. Le principe : transporter la donnée vers une poignée d’immenses data centers pour la stocker d’abord et la traiter ensuite. Après cela seulement, le résultat du calcul s’en retourne vers l’utilisateur final. Mais cette architecture centralisée possède des défauts. En particulier des latences liées à la bande passante. Et avec l’arrivée de technologies comme la voiture connectée ou l’Internet-des-Objets, le fonctionnement arrive à ses limites.
“Certaines données périment et perdent leur pertinence si elles ne sont pas traitées immédiatement. Il faut donc un traitement ‘en ligne’, un traitement dans l’instant. Mais cela passe par un changement de paradigme,” résume Daniel Balouek. Ce chercheur Inria fait partie de Stack*, une équipe posant les fondations d’un nouveau modèle qui, au-delà du cloud, s’étend sur tout le continuum numérique et exploite quantité d’autres ressources de calcul présentes tout au long du réseau, y compris une kyrielle d’appareils situés sur ses terminaisons (le ‘edge’).
Dans ce contexte, Daniel Balouek s’intéresse plus particulièrement à l’informatique d’urgence. Il s’agit d’un type d’applications s’appuyant sur le continuum pour faciliter la prise de décisions en cas de catastrophes naturelles et autres événements extrêmes. “Dans ces domaines, certaines applications existent depuis longtemps. Elles mériteraient d’être revisitées avec les moyens de notre époque. Malheureusement, il n’y a pas forcément de modèle économique incitant à la modernisation comme on peut en voir, par exemple, dans l’e-commerce.”
En 2020, avec deux collègues du Rutgers Discovery Informatics Institute, Daniel Balouek a proposé une application de détection de tremblements de terre* pour illustrer le concept et les mérites d’une analyse distribuée exploitant une infrastructure dynamique sur ce continuum numérique. L’outil combine des flux de données en provenance de sismomètres et de stations GPS haute précision géodistribués permettant de détecter de grands mouvements de la croûte terrestre*. Cette publication a été primée dans la catégorie ‘impact social de l’IA’ durant l’une des principales conférences sur l’intelligence artificielle.
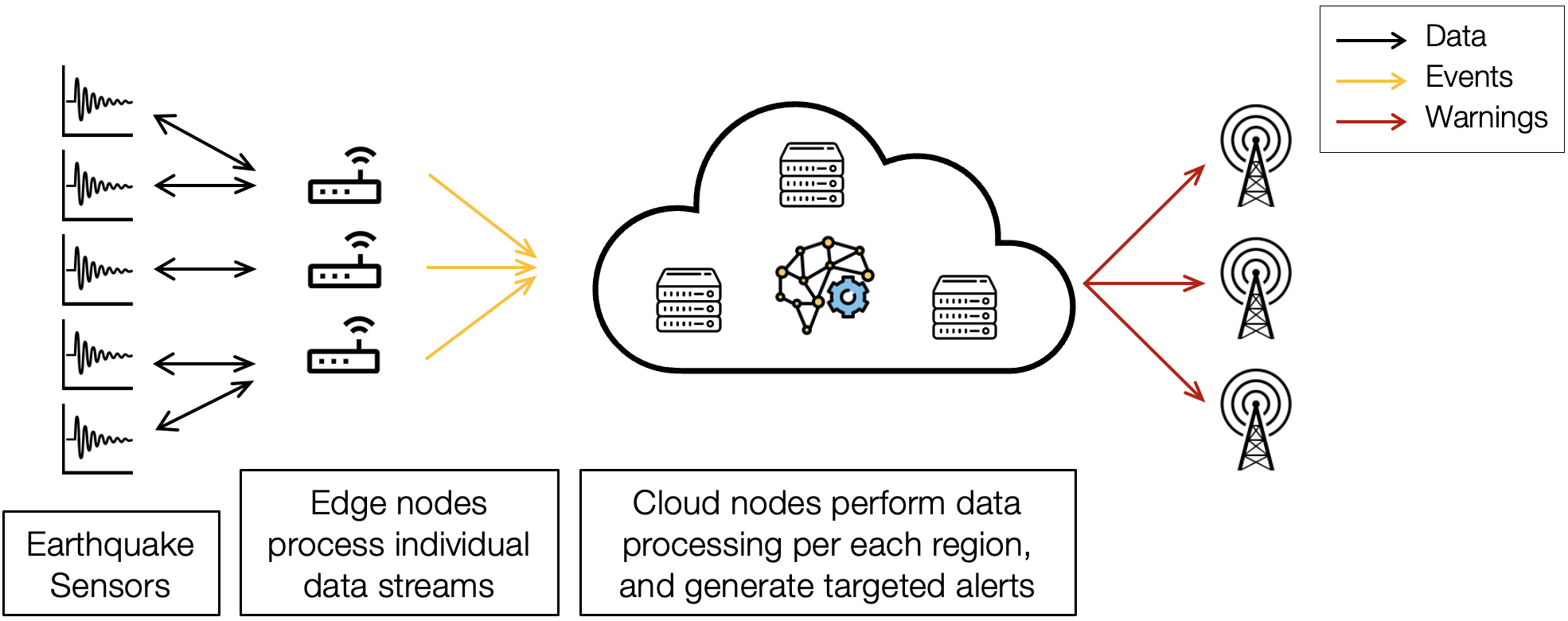
Exploiter le continuum implique une utilisation efficace des ressources de calculs sur le chemin de la donnée afin d’effectuer des compromis entre la rapidité des traitements et la qualité des résultats obtenus
Traiter la donnée au plus près des capteurs
Le scénario émule 1000 capteurs déployés sur 25 machines. Chaque groupe de 20 capteurs représente une région géographique. Un capteur produisant 1200 messages à 100 Hz, il faut analyser… 12 millions de messages en un clin d’oeil. Au lieu de partir vers le cloud, ces données font l’objet d’un premier traitement de classification à proximité des capteurs. “Cela permet d’augmenter le niveau de confiance dans les résultats. Différentes stations détectent des phénomènes. Une secousse par-ci. Une secousse par-là. On a cette intelligence collective grâce à laquelle plusieurs stations détectent un incident et parviennent à établir que c’est un tremblement de terre. Une détection locale intervient donc avant que les données ne soient agrégées dans le cloud.” De plus, si le séisme met le data center hors service, l’application va continuer son travail et s’adapter dynamiquement aux capacités de calcul encore disponibles.
Les recherches comprennent deux aspects. Le premier porte sur la gestion de la ressource : trouver les machines disponibles, y répartir le calcul, assembler des fédérations dans lesquelles chacun peut amener ou retirer ses moyens comme il l’entend, etc. “Pour l’instant, on a tendance à construire un système pour les séismes, un autre pour les inondations, et encore un autre pour les feux de forêts. Or la logique serait plutôt de réutiliser les ressources déjà existantes en privilégiant des plateformes partagées. Malheureusement, c’est au moment de l’accident que l’on va chercher à spécialiser nos ressources. Tout à coup, le scientifique affronte une situation d’urgence à quoi s’ajoute le besoin de trouver des moyens de calculs. Un séisme se produit. Qui peut m’aider à faire du calcul ? Puis-je réorienter des ressources affectées au départ à un autre but ? Par exemple des ordinateurs servant à la gestion des stocks ? Puis-je accéder à des appareils dont le but premier était la vidéo surveillance ou la mesure de la qualité de l’air ? Comment ces moyens peuvent-ils devenir des ressources de calcul urgent pour une nouvelle situation ?”
Sur ce type de plateformes partagées, “le fait de prioriser les choses va s’avérer crucial. Car l’urgence de l’un n’est pas forcément l’urgence de l’autre. Si un feu et une tornade se déclenchent en même temps, il faut prendre des décisions. Donner des priorités en fonction des règles et protocoles de la gestion de crise. Nous allons devoir intégrer cette notion de hiérarchie et proposer des outils de visualisation pour aider à cette prise de décision.”
Pair-à-Pair
Dans cette orchestration, les mécanismes de communication Pair-à-Pair jouent un rôle important. “Pensez à la voiture connectée. Imaginez que vous perdez la connexion au serveur central du constructeur, au Japon. Grâce au Pair-to-Pair, votre voiture continue de recevoir des informations partagées par les véhicules des alentours. Vous restez dans une bulle d’informations.”
Nouveaux modèles de programmation
Le deuxième aspect des travaux concerne les modèles de programmation pour faciliter l’usage des ressources. “A l’heure actuelle, c’est relativement facile de construire une application sur le cloud. Un développeur avec deux ans de formation peut utiliser le cloud d’Amazon où des abstractions logicielles et des modèles simplifient grandement le travail. Mais sur le continuum, ce n’est pas aussi facile. Il y a plus de dynamicité et les développeurs n’ont pas forcément la propriété ou le contrôle des ressources qu’ils utilisent. Si j’écris un programme de détection sismique qui marche bien en France et que je souhaite le réutiliser au Japon, avec une situation et des ressources nouvelles, il faut que le modèle soit assez intelligent pour pouvoir s’adapter rapidement au changement de contexte.”
Autre souci : optimiser l’équilibre entre ressources utilisées et qualité de traitement. Exemple : “en vidéo, les caméras Full HD produisent beaucoup d’images à la seconde. Mais beaucoup d’applications n’ont besoin que de deux ou trois vues à la seconde pour fonctionner. Cela va libérer de la ressource pour autre chose. Si nous utilisons nos algorithmes en faible résolution, ils travaillent plus vite ou effectuent plus de tâches simultanément. Nous libérons aussi de la bande passante. Donc, il y a ce compromis à trouver entre ce que je souhaite faire et ce que je peux vraiment faire, soit de par mon infrastructure, soit de par les contraintes que je m’impose.”
À la recherche de cas d’usage
Pour avancer les recherches, Daniel Balouek est friand de collaborations avec des scientifiques du terrain. “Si nous voulons construire ces modèles de programmation, il nous faut les utilisateurs dans la boucle. Nous devons travailler avec eux la main dans la main. Nous les invitons donc à nous présenter leur cas d’usage. Si nous avons déjà des solutions, parfait. Nous partagerons notre expérience. Dans le cas contraire, cela pourrait être l’occasion de lancer une recherche conjointe. Nous avons un questionnaire bien rôdé pour servir de point de départ. Qu’est-ce qui marche ? Qu’est-ce qui ne marche pas ? Les scientifiques ont déjà des solutions existantes et leur expertise propre. Notre but n’est pas de tout révolutionner mais de répondre aux questions de ceux qui essayent de se projeter dans l’avenir. Par exemple, nous pourrions pointer que dans 10 ans, le prix de l’énergie rendra les data centers moins abordables. Cela vaut donc peut-être la peine de s’intéresser à notion de compromis en commençant déjà à réfléchir à une nouvelle solution.”
À moyen terme, Daniel Balouek souhaite élaborer une road map pour assembler ces applications d’une façon générique à l’aide de briques conçues pour différentes tâches. “Nous essayons de nous concentrer sur des opérations de base. Comment collecter les données. Comment les déplacer. Ce sont des primitives dont tous les scientifiques ont besoin à un moment ou à un autre. Le but est d’automatiser un maximum de choses. Mais pas de retirer l’humain de la boucle car on a toujours besoin de l’expertise du scientifique. Nous souhaitons automatiser un maximum de choses pour que notre utilisateur ne soit pas contraint d’ouvrir son répertoire de code, mais qu’il se retrouve plutôt avec des métriques de haut niveau présentées de façon intelligible. Il pourra ainsi travailler sur les métriques applicatives de son domaine.”
Le champ d’application dépasse d’ailleurs l’informatique d’urgence. “Au niveau industriel, il y a un intérêt pour le jumeau numérique, par exemple. Quand un feu se déclare dans un bâtiment, pouvoir observer une situation en temps réel et avoir un jumeau numérique va aider les pompiers à progresser dans les lieux enfumés, à atteindre des pièces spécifiques, à aller chercher certains objets. L’application peut ainsi guider l’intervention. Et il y a beaucoup de cas similaires où les gens qui interviennent pour la sécurité civile peuvent bénéficier de ce genre d’outils.”
- STACK est une équipe commune d’Orange, d’Inria, d’IMT Atlantique et de Nantes Université au sein du Laboratoire de sciences numériques de Nantes (LS2N).
- Lire : Harnessing the computing continuum for urgent science, par Balouek, D., Rodero, I. et Parashar, M. dans ACM SIGMETRICS Performance Evaluation Review, 2020.
- Lire : A distributed multi-sensor machine learning approach to earthquake early warning, par Fauvel, K., Balouek, D., Melgar, D., Silva, P., Simonet, A., Antoniu, G., Costan, A., Masson, V., Parashar, M., Rodero, I. et Termier, A. Outstanding Paper Award in Artificial Intelligence for Social Impact, actes de la conférence AAAI Conference, 2020