Abstract:
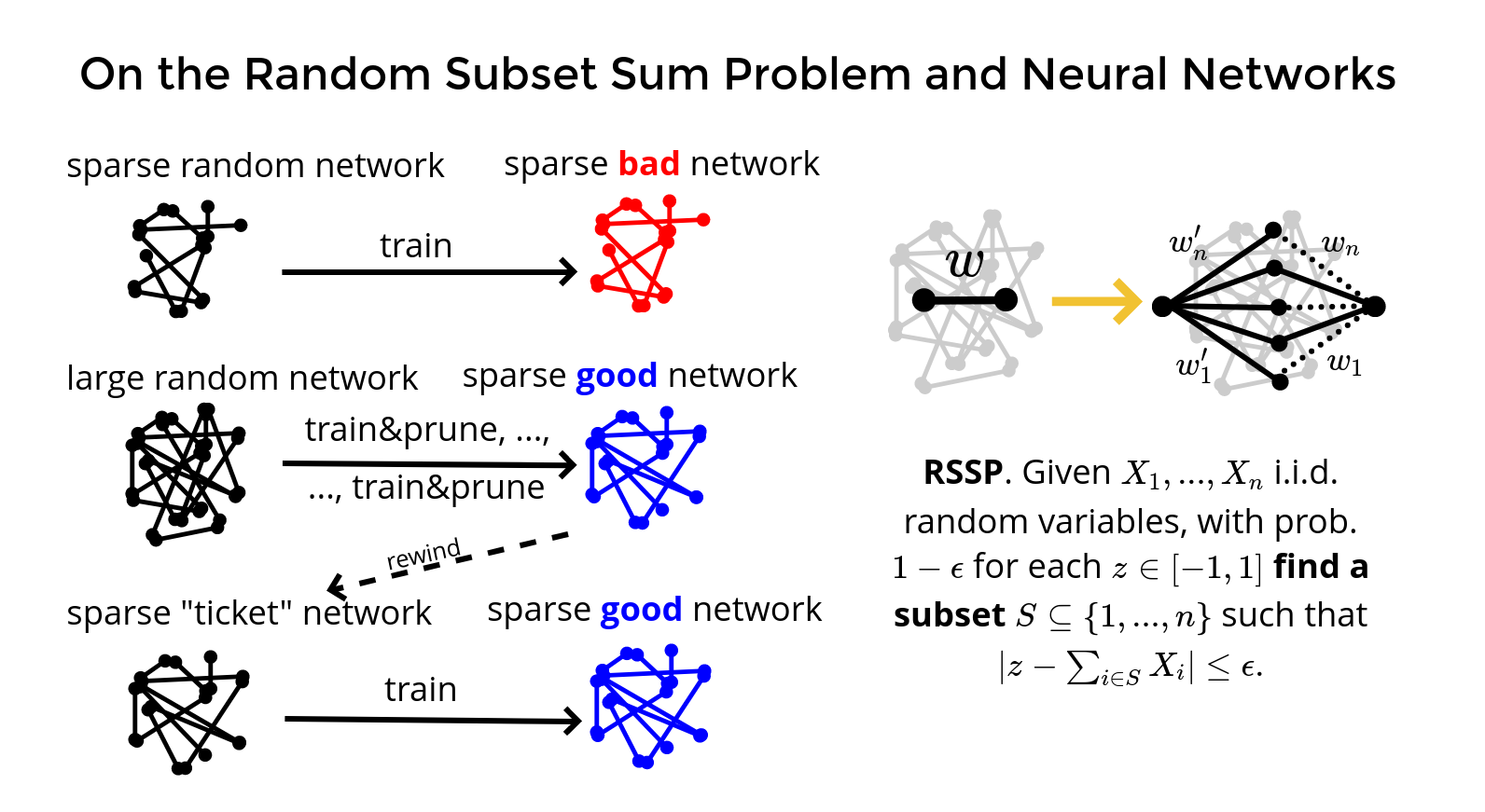
The Random Subset Sum Problem (RSSP) is a fundamental problem in mathematical optimization, especially in understanding the statistical behavior of integer linear programs.
Recently, the theory related to this problem has also found applications in theoretical machine learning, providing key tools for proving the Strong Lottery Ticket Hypothesis (SLTH) for dense neural network architectures. In this talk, I will give a brief overview of this research direction and present my recent joint work that pushes the application of RSSP further by providing a proof of the SLTH for convolutional neural networks.

Bio:
Before accepting a CNRS position in 2018 and joining the I3S Lab and INRIA d’Université Côte d’Azur, Emanuele Natale has been a fellow of the Simons Institute for the Theory of Computing in the Brain and Computation Program and a postdoctoral fellow at the Max Planck Institute for Informatics. In 2019, He has received the Best Italian Young Researcher in Theoretical Computer Science award by the Italian Chapter of the European Association of Theoretical Computer Science, from which he also received the Best PhD Thesis in Theoretical Computer Science in 2017. In 2016, he has been a recipient of the Best Student Paper Award at the European Symposium on Algorithms.
Emanuele Natale’s research originally focused on the mathematical analysis of simple distributed probabilistic algorithms that allow multi-agent systems to solve global coordination tasks, with applications spanning machine learning, sociology and theoretical biology. More recently, his research interests have shifted mainly to neuroscience and machine learning, with a focus on the role of sparsification in neural networks.
The presentation will be in English and streamed on BBB